Snapshot vs Clone in Storage
Terms related to simplyblock
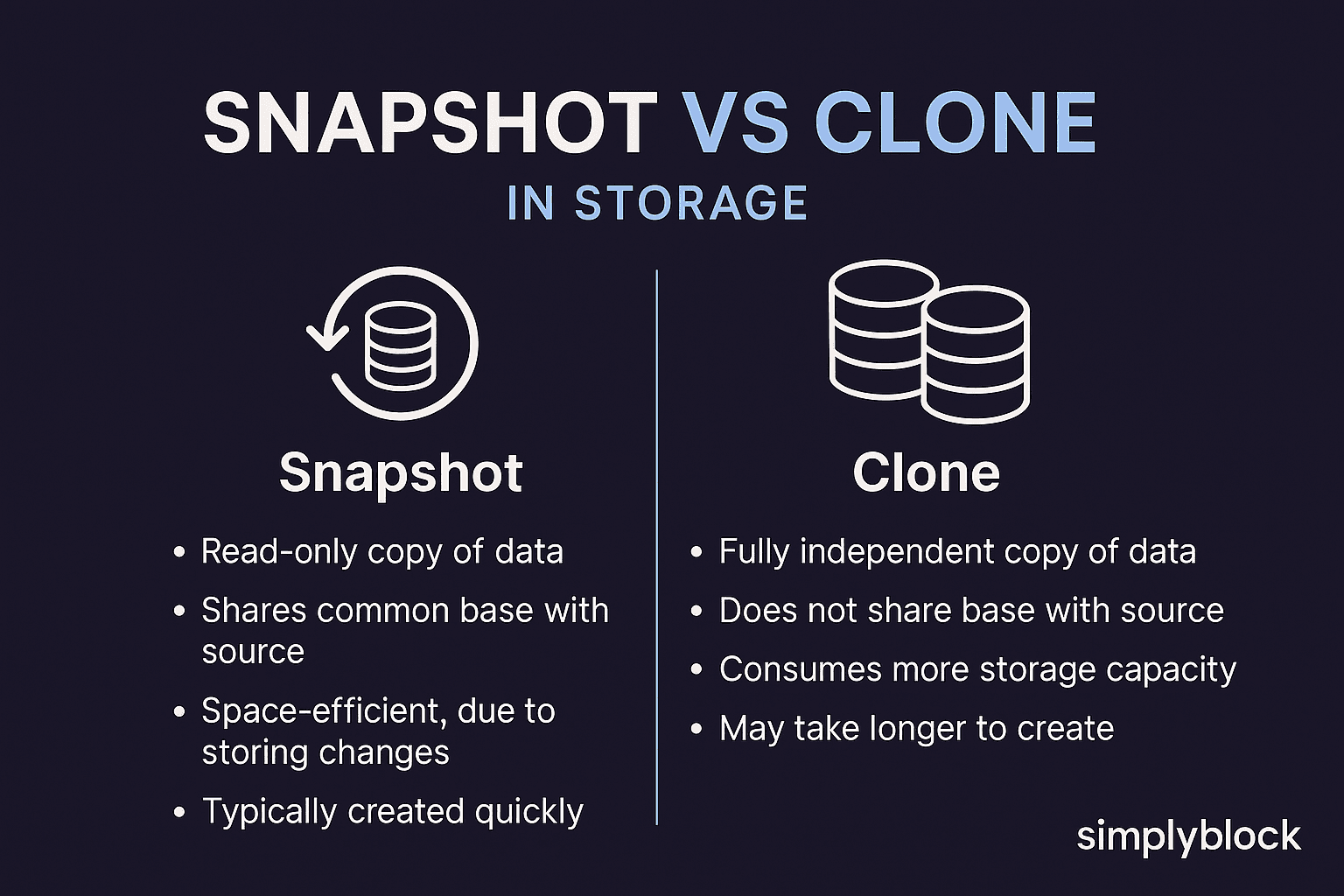
Snapshot and clone are two essential data management capabilities used in storage systems to protect, replicate, and manipulate data without disrupting production workloads. While they may seem similar, each serves distinct purposes.
- A snapshot is a point-in-time, read-only or read-write copy of a volume. It captures the state of the data at that specific moment using metadata and Copy-on-Write (CoW) mechanisms.
- A clone is a writable copy of an existing volume or snapshot. It is a fully functional, independent volume that can be used by separate workloads.
Platforms like simplyblock support both instant snapshots and zero-copy clones for Kubernetes persistent volumes, enabling rapid scaling, rollback, and testing.
What is a Storage Snapshot?
A snapshot captures the exact state of a volume at a given time without copying the entire dataset. Instead, it tracks the delta (differences) between the snapshot and future changes using Copy-on-Write (CoW).
Key characteristics:
- Snapshots are often used for rollback, disaster recovery, or backup consistency.
- They can be read-only (common for backups) or read-write (for cloning).
- Snapshots are space-efficient and fast to create.
- They do not impact running applications during creation.
In Kubernetes, CSI-compliant snapshots are managed via VolumeSnapshot and VolumeSnapshotClass APIs.
What is a Storage Clone?
A clone is a new, independent volume created from an existing volume or snapshot. Clones are writable from the start and are used when you need to replicate a dataset for use by another process or application.
Typical use cases:
- Create a temporary test or staging environment from production data.
- Duplicate data for analytics, development, or migration.
- Enable fast, space-saving scaling in Kubernetes StatefulSets.
Cloning relies on snapshot technology internally, but results in a new volume that persists even if the source is deleted.
Snapshot vs Clone: Key Differences
Below is a technical comparison of snapshot and clone features in modern storage systems:
| Feature | Snapshot | Clone |
|---|---|---|
| Mutability | Read-only or read-write | Always writable |
| Storage Efficiency | Very high (CoW-based) | High (uses shared blocks initially) |
| Creation Speed | Instant | Near-instant |
| Use Case | Backup, rollback, consistency | Dev/test, duplication, migration |
| Dependency | Tied to source volume | Initially tied, then independent |
| Kubernetes Support | CSI VolumeSnapshot | CSI VolumeClone (if supported) |
| Impact on Performance | Minimal during creation | Minimal, increases with divergence |
Benefits of Snapshots and Clones in Kubernetes
Using snapshots and clones with Kubernetes provides significant operational advantages:
- CI/CD acceleration: Create test environments instantly with cloned data.
- Data protection: Use snapshots for safe backups and recovery points.
- Storage agility: Clone stateful workloads like PostgreSQL or Cassandra without full-volume duplication.
- Space efficiency: CoW mechanisms ensure minimal storage impact.
Simplyblock supports both via CSI-based Kubernetes storage, enabling rapid recovery, scalability, and cost-effective provisioning.
Snapshot and Clone in Simplyblock
Simplyblock offers snapshot and clone functionality integrated into its high-performance block storage stack:
- Instant snapshots with no IOPS degradation
- Writable zero-copy clones from any snapshot or live volume
- CSI-native implementation compatible with OpenShift, Rancher, and Amazon EKS
- Works with erasure-coded volumes for fault tolerance
- Integrated with multi-tenancy and QoS for role-based data access
This architecture ensures full data lifecycle management across edge, hybrid, and cloud deployments.
Related Terms
Teams often review these glossary pages alongside Snapshot vs Clone in Storage when they implement Copy-on-Write data paths, control copy sprawl, and keep restore and dev-test workflows predictable in Kubernetes Storage.
Copy-On-Write (CoW)
Database Branching
Storage Latency
Write-Ahead Log (WAL)
External Resources
- Kubernetes Volume Snapshots – Official Docs
- CSI Volume Cloning – Kubernetes
- Snapshot vs Clone – Red Hat
Questions and Answers
A snapshot is a read-only, point-in-time copy of a volume, while a clone is a writable, fully functional copy. Snapshots are ideal for backups and quick restores; clones are best for testing, staging, or duplicating workloads without impacting the original data.
Use snapshots for fast recovery or backup strategies, especially when leveraging CSI snapshot support. Clones are better for spinning up test environments or scaling stateful apps with persistent volumes.
Both can affect performance depending on the implementation. Snapshots are typically lightweight, especially when using copy-on-write. Clones may increase I/O if heavily modified. NVMe over TCP storage can help minimize this impact by delivering high throughput.
Yes. When encryption at rest is enabled at the volume level, both snapshots and clones inherit the same encryption policies—ensuring data remains protected in all states, even in multi-tenant environments.
Absolutely. Snapshots are often taken first, then used to create clones for dev/testing or data migration. This layered approach is common in software-defined storage to enable safe, efficient workflows without downtime.