Software-Defined Everything (SDx)
Terms related to simplyblock
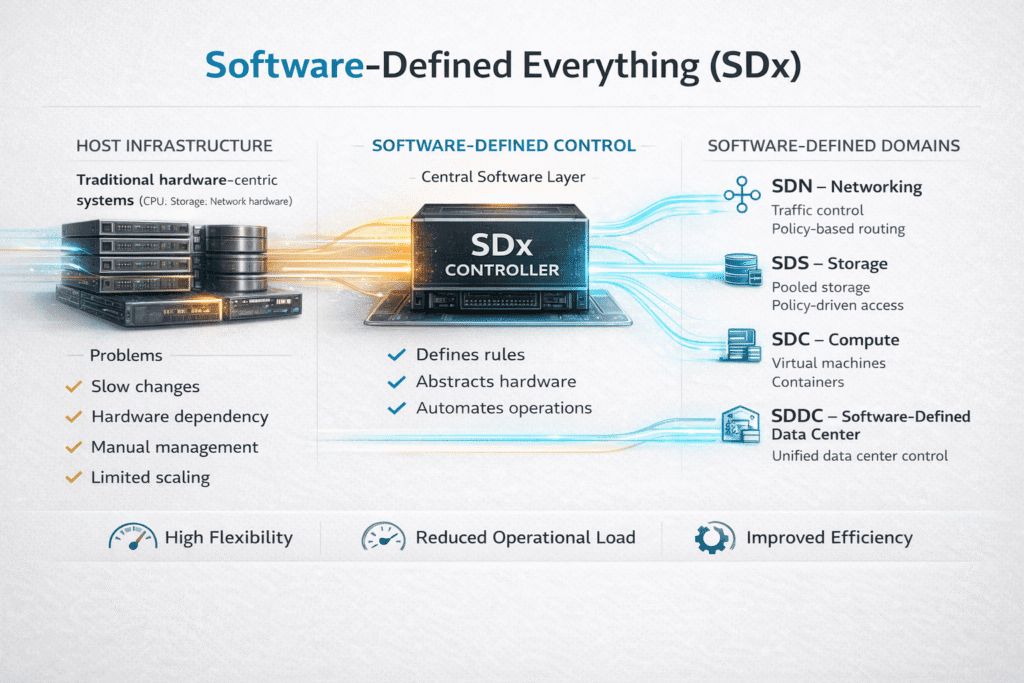
Software-Defined Everything (SDx) is an infrastructure approach that moves control and policy out of fixed hardware and into software. Teams use SDx to standardize how they provision compute, networking, and Software-defined Block Storage across baremetal, virtualized, and cloud environments.
SDx matters most when platforms need to scale without redesigning the data center. Instead of buying a bigger array or a bigger chassis, operators scale out with commodity servers, NVMe, and an automation layer that enforces placement, resiliency, and performance targets. In executive terms, SDx shifts spend from proprietary hardware cycles to repeatable operations, clearer cost drivers, and faster time to capacity.
For Kubernetes Storage, SDx becomes the control plane for data, not just for pods. It determines how volumes get placed, how they fail over, and how they behave under load when multiple tenants share the same cluster.
🚀 Run Software-Defined Everything (SDx) on NVMe/TCP, Natively in Kubernetes
Use Simplyblock to standardize Kubernetes Storage with Software-defined Block Storage and predictable QoS.
👉 Use Simplyblock for Software-Defined Storage (SDx) →
Optimizing SDx with Modern Infrastructure Platforms
SDx optimization starts with removing “special snowflake” infrastructure. Most bottlenecks come from slow control paths, noisy neighbors, and too many copies between the application and the media. Modern SDx designs focus on three ideas: disaggregation, policy-based automation, and fast data paths.
A practical SDx platform exposes APIs that map to business intent, such as “gold latency,” “bronze cost,” or “regulated data,” and then enforces those intents through scheduling, QoS, encryption, and replication. Operators gain leverage when the platform also supports NVMe-oF protocols and integrates with container and VM stacks without forcing a single deployment model.
SDx in Kubernetes Storage Architectures
SDx changes Kubernetes Storage from “a driver that mounts a disk” into a fabric that serves many workload types. A CSI integration handles lifecycle, but the architecture decides whether you get predictable latency.
Hyper-converged SDx places storage services on the same nodes that run workloads. This can reduce network hops, and it often fits edge clusters and smaller footprints. Disaggregated SDx runs storage on dedicated nodes and serves volumes over the network, which usually improves fleet utilization and makes scaling cleaner. Hybrid designs mix both, so teams can keep hot paths close while still pooling capacity for everything else.
When you evaluate SDx for Kubernetes, look past raw IOPS. Ask how the platform controls tail latency, how it isolates tenants, and how it behaves during node drains, reschedules, and rolling upgrades.
SDx and NVMe/TCP Fabrics
NVMe/TCP brings NVMe semantics across standard Ethernet, which makes it attractive for SDx in production. It can run on existing network gear, and it tends to fit cloud-native operations because it avoids specialized RDMA fabrics in many environments.
In SDx, NVMe/TCP becomes a building block for disaggregated Software-defined Block Storage. It lets storage nodes serve volumes to Kubernetes workers, database VMs, and baremetal apps using a single transport that most network teams already know how to operate. For organizations that want maximum performance, many SDx stacks also support NVMe/RDMA, and you can segment workloads by storage class and fabric.
Measuring and Benchmarking Software-Defined Everything (SDx) Performance
Benchmarking SDx requires a method that matches real workloads. Measure throughput, IOPS, and latency, but also track p95 and p99 latency because your application feels the tail, not the average.
For Kubernetes Storage, include tests that simulate noisy neighbors, reschedules, and multi-volume patterns. Run short burst tests and longer steady-state tests. Make sure you capture CPU utilization per I/O path, because a storage stack that burns cores can look fast in isolation and then collapse when the cluster gets busy.
Tools like fio can help, but the test design matters more than the tool. Align block size, queue depth, read/write mix, and number of jobs to how your databases, analytics, or CI pipelines actually hit storage.
Approaches for Improving SDx Performance Under Load
Teams improve SDx performance by tightening the data path and enforcing resource boundaries. The fastest fixes usually come from eliminating kernel overhead where possible, reducing copies, and applying QoS at the right layer.
Use this short checklist as a starting point (the order reflects what typically shows impact first):
- Reduce CPU overhead with user-space I/O stacks (for example, SPDK-style polling) to keep latency stable under concurrency.
- Separate control plane and data plane concerns, so metadata operations do not interrupt hot I/O paths.
- Enforce multi-tenant QoS with per-volume limits and priorities, and validate isolation with mixed-workload tests.
- Match media to workload, such as NVMe for latency-sensitive volumes and higher-density SSD tiers for capacity pools.
- Tune the network for storage traffic, including MTU consistency, congestion behavior, and clear separation between east-west storage and general service traffic.
SDx Storage Deployment Models
The SDx deployment model shapes both cost and risk. This table summarizes common patterns used for Kubernetes Storage and Software-defined Block Storage in enterprise environments.
| SDx deployment model | Where storage runs | Best fit | Typical trade-off |
|---|---|---|---|
| Hyper-converged | On Kubernetes worker nodes | Edge, smaller clusters, local performance | Scaling storage can force scaling compute |
| Disaggregated | On dedicated storage nodes | Large fleets, better pooling, SAN alternative | Depends more on network design |
| Hybrid | Both worker and storage nodes | Mixed workloads, phased migrations | Requires clear policy and observability |
Delivering Deterministic Storage Performance with Simplyblock™
Deterministic performance needs more than fast media. It needs a design that keeps the data path efficient, enforces isolation, and scales without “cliff effects.”
Simplyblock targets that outcome with an SPDK-based, user-space architecture that reduces kernel overhead and avoids extra copies in the I/O path. That design choice aligns well with NVMe-oF goals, including NVMe/TCP, because it keeps CPU cost per I/O low as concurrency rises. In Kubernetes Storage, simplyblock supports hyper-converged, disaggregated, and hybrid deployments, so platform teams can place performance where it matters while still pooling capacity across clusters.
Enterprises also care about governance. simplyblock adds multi-tenancy and QoS so teams can run multiple application groups on shared Software-defined Block Storage without accepting unpredictable latency. When a platform roadmap includes DPUs or IPUs, the same “move work off the host CPU” philosophy can extend into hardware offload strategies.
Next-Phase SDx – Policy-Driven Control, Offload, and Fabric Evolution
SDx continues to move toward policy-driven operation. Storage classes, placement rules, and SLO targets increasingly define behavior, while the platform automates the mechanics. Offload also becomes more common as organizations adopt DPUs, IPUs, and faster fabrics, because reducing CPU time per I/O helps both cost and predictability.
On the fabric side, NVMe/TCP remains a practical default for broad compatibility, and high-performance environments often add NVMe/RDMA for specific tiers. The direction stays the same: fewer copies, fewer context switches, clearer isolation, and better observability tied to business-facing objectives.
Related Terms
Teams often review these glossary pages alongside Software-Defined Everything (SDx) when they optimize Kubernetes Storage and Software-defined Block Storage data paths, plus CPU offload strategies for NVMe/TCP fabrics.
Zero-Copy I/O
SmartNIC vs DPU vs IPU
PCIe-based DPU
Infrastructure Processing Unit (IPU)
Questions and Answers
SDx enables fully programmable infrastructure by abstracting compute, networking, and storage into software-defined layers. This allows organizations to automate deployments, scale dynamically, and optimize resource usage—key for environments like Kubernetes, multi-cloud, or edge computing.
Traditional infrastructure depends heavily on fixed-function hardware, while SDx uses software to manage and orchestrate resources flexibly. With SDx, teams gain faster provisioning, centralized control, and better scalability—ideal for DevOps, CI/CD pipelines, and modern cloud-native applications.
Software-Defined Storage decouples the control and data planes, enabling you to run high-performance storage on standard hardware. SDS supports automated provisioning, snapshots, replication, and integration with Kubernetes—all key features for building resilient, scalable SDx architectures.
Yes, SDx aligns perfectly with Kubernetes. Software-defined storage, compute, and networking integrate via APIs and the Container Storage Interface (CSI), enabling seamless scalability, multi-tenant isolation, and automation—critical for production-grade Kubernetes setups.
An SDx stack includes SDS, SDN (Software-Defined Networking), software-defined compute, and orchestration tools. It’s often built on container orchestration platforms like Kubernetes and integrates with cloud-native tools for monitoring, policy enforcement, and automation.