Stateful Workloads on Kubernetes
Terms related to simplyblock
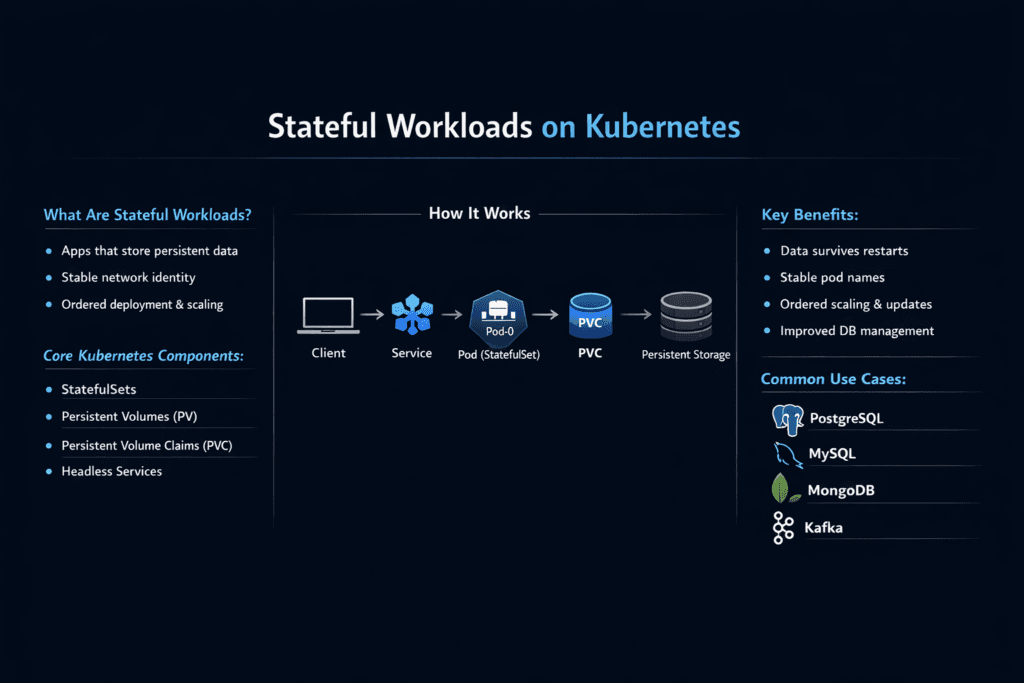
Stateful Workloads on Kubernetes are applications that must keep data, identity, and ordering across restarts and reschedules. Databases, queues, search indexes, and stream processors fall into this group. When a pod restarts, the app expects the same data to appear on the same volume, with the same write rules, and with stable latency.
Teams succeed with stateful platforms when storage and scheduling work together. Kubernetes Storage manages the volume lifecycle via CSI, while the app requires steady I/O during deploys, node drains, and failures. A Software-defined Block Storage layer reduces friction by scaling on standard hardware and supporting policy controls for durability and performance.
Building reliable stateful platforms with cloud-native patterns
Stateful apps fail in predictable ways when the platform treats them like stateless services. A reschedule can attach the wrong volume. A rollout can trigger a slow reattach. A busy neighbor can push latency out of bounds. These issues show up as stalled writes, long leader elections, and rising replication lag.
Cloud-native patterns help when you apply them with intent. Use declarative storage classes, clear access modes, and repeatable topology rules. Keep failure domains explicit, and test upgrades with live I/O. Also treat tail latency as a first-class KPI, not an afterthought. If you only watch averages, you will miss the spikes that break databases first.
🚀 Stop Noisy Neighbors From Breaking Stateful Services
Use Simplyblock QoS to protect critical volumes and keep latency under control.
👉 Use Simplyblock for Multi-Tenancy and QoS →
Stateful Workloads on Kubernetes in Kubernetes Storage
Kubernetes runs most stateful apps through StatefulSets or operators. Those controllers rely on stable volume claims and predictable attach behavior. The platform must preserve identity, keep mounts consistent, and manage ordered startup when the app needs it.
Storage decisions drive day-2 outcomes. Volume expansion must work online. Snapshots must complete quickly and safely. Drains must not strand pods waiting on a stuck detach. When the storage layer handles these tasks cleanly, teams ship changes faster and cut incident time.
Multi-tenant clusters add another challenge. One noisy workload can steal I/O budget from others. Strong QoS and clear limits protect critical services during compaction, rebuild, and backup windows.
Stateful Workloads on Kubernetes and NVMe/TCP
NVMe/TCP gives stateful platforms a strong data path over standard Ethernet. It supports high parallelism and fits both hyper-converged and disaggregated designs. Teams often choose it because it scales without special fabrics and aligns with common network operations.
Protocol choice still leaves work for the storage stack. Stateful apps punish jitter, so the I/O path must stay lean under load. Efficient user-space I/O helps here because it reduces copies and lowers CPU cost per operation. That extra headroom matters during peaks and during recovery, when the cluster needs to heal while serving live traffic.
Measuring Stateful Workloads on Kubernetes performance
Measure what users feel, not what a benchmark headline shows. Stateful apps care about p95 and p99 latency, not only IOPS. They also care about how latency behaves during checkpoints, compaction, rebalances, and backups.
A useful test plan keeps the workload running while the platform changes. Run a steady read/write mix, then trigger a node drain or a controlled failure. Track latency, throughput, and time-to-recover. Repeat the same test at higher pool usage because many systems degrade when capacity runs hot.
Operational tactics that reduce outages and latency spikes
Use a small set of tactics that directly reduce risk for stateful services:
- Set QoS per volume so rebuild and backup traffic cannot consume the full latency budget.
- Match access modes and topology rules to the app’s write pattern and failure domain.
- Keep the expansion and snapshot workflows routine, and validate them during normal business load.
- Separate hot data from bulk data with tiers, and reserve the lowest-latency tier for write-heavy services.
- Run chaos-style tests for drains and failures so you can trust the platform during upgrades.
Comparing common storage approaches for stateful apps
This table compares typical ways teams run stateful services in Kubernetes. It highlights operational effort, latency stability, and recovery behavior.
| Approach | Latency stability | Scaling model | Upgrade and drain behavior | Best fit |
|---|---|---|---|---|
| Local SSD per node | Strong until a node fails | Scale with compute | Drains can force data moves | Edge, single-node caches |
| Managed cloud block | Varies by tier and neighbor load | API-driven | Easy start, less control | Small to mid fleets |
| Traditional SAN | Often steady, depends on fabric | Scale-up focus | Change cycles can slow teams | Central IT, stable stacks |
| Software-defined Block Storage on NVMe | Strong with QoS and clean I/O | Scale-out | Fast automation, safer rollouts | Shared platforms, database fleets |
Stateful Workloads on Kubernetes with Simplyblock™
Simplyblock™ targets stateful platforms that need stable latency and clean operations. It provides Software-defined Block Storage for Kubernetes Storage with an NVMe-first design, plus policy controls for multi-tenancy and QoS. Teams can isolate critical volumes, control rebuild pressure, and keep noisy neighbors in check.
Its SPDK-based user-space data path helps reduce overhead in the I/O stack. That design can improve CPU efficiency and tighten tail latency when clusters run hot. With NVMe/TCP support, simplyblock also fits disaggregated or mixed deployments, so teams can scale storage nodes without forcing application redesign.
What changes next for running stateful services on Kubernetes
Stateful platforms will keep moving toward stronger guardrails. Teams will codify SLOs for p99 latency, enforce QoS by default, and automate safe expansion. Operators will also demand clearer visibility into I/O paths, rebuild rates, and per-tenant impact.
Hardware offload will grow in importance as well. DPUs and IPUs can take on more networking and data-path tasks, which can reduce CPU jitter on application nodes. As these patterns spread, platforms that keep operations simple and I/O steady will set the baseline for stateful Kubernetes at scale.
Related Terms
Teams reference these related terms when they design Kubernetes platforms for stateful services.
Stateful Application in Kubernetes
Block Storage for Stateful Kubernetes Workloads
Kubernetes StatefulSet
Storage Metrics in Kubernetes
Questions and Answers
Stateful workloads in Kubernetes are applications that require persistent storage and stable network identities, such as databases or messaging systems. These workloads rely on durable volumes provisioned through a Kubernetes-native storage platform to maintain data consistency across pod restarts.
Unlike stateless apps, stateful workloads require low latency, high IOPS, and data durability. Architectures based on distributed block storage ensure resilience and performance even during scaling or node failures.
NVMe over TCP provides high-performance block storage over standard Ethernet, enabling low-latency access for databases and transactional systems running in Kubernetes clusters.
PersistentVolumeClaims (PVCs) and StorageClasses define how storage is provisioned and attached. Simplyblock integrates via CSI to support advanced features like replication and encryption for stateful Kubernetes workloads.
Simplyblock delivers software-defined, NVMe-backed storage with dynamic provisioning and horizontal scaling. Its scale-out storage architecture ensures consistent performance and high availability for growing production workloads.