Storage Rebalancing
Terms related to simplyblock
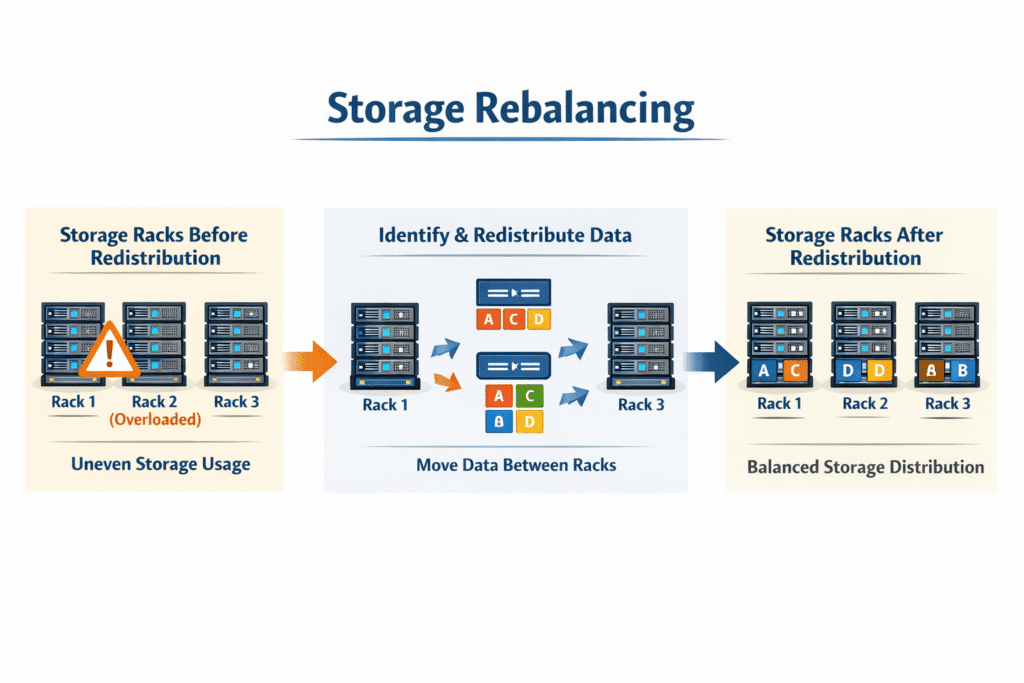
Storage rebalancing moves data so that nodes and drives carry a similar share of capacity and work. Clusters start it after you add hardware, remove hardware, or lose a drive or node. The goal stays simple: prevent hot spots, spread free space, and keep latency steady while the cluster shifts.
When rebalancing runs too aggressively, apps feel it right away. p99 latency can jump because background copy traffic competes with foreground reads and writes.
Why Clusters Drift Out of Balance
Balance slips for normal reasons. One node fills faster because it hosts more busy volumes. A failure forces the system to rewrite chunks elsewhere. A new node joins with empty drives, so the cluster needs to move data to use it.
Good rebalancing fixes the skew by moving the right data at the right pace. It also avoids pointless churn by using placement rules that keep data evenly spread in the first place.
🚀 Keep Storage Rebalancing From Spiking Tail Latency in Kubernetes
Use Simplyblock to automate online rebalancing with QoS controls, so background movement doesn’t steal your app’s I/O budget.
👉 Use Simplyblock for Scale-Out Architecture →
Storage Rebalancing in Kubernetes Storage
Kubernetes adds churn on top of storage events. Pods reschedule, nodes drain, and StatefulSets roll. Those changes can overlap with device adds, node adds, or recovery after a fault.
A Kubernetes-ready storage layer needs two things during movement: stable access to volumes and stable performance per tenant. CSI helps with lifecycle, but the backend still has to throttle background work so it does not steal the I/O budget from stateful apps.
NVMe/TCP Paths and Background Data Movement
NVMe/TCP puts block I/O on Ethernet, so network headroom becomes part of your rebalance plan. Data movement, rebuild traffic, and client I/O can share the same links and CPU cycles.
Smart pacing matters more than raw speed. If the cluster rushes to even out, it can crowd out client I/O and raise tail latency. If it moves too slowly, the cluster stays uneven longer and carries more risk.
How to Benchmark Rebalance Impact Under Load
A useful test has three phases: before, during, and after. First measure steady-state latency (p95/p99), IOPS, throughput, and CPU. Then trigger a rebalance event, such as adding a drive or simulating a device loss. Finally, measure how fast the system returns to a stable state and how much latency drifts while movement runs.
Track two results at once: time-to-balance and time-to-stable-latency. Fast balance does not help if it causes repeated p99 spikes.
Controls That Keep Rebalancing Fast Without Hurting Apps
Start with clear priorities. Foreground I/O should win when apps need it. Background copy work should use the slack.
Rate limits do most of the heavy lifting. Many platforms cap rebuild bandwidth, cap recovery IOPS, or schedule heavier movement during quiet hours. Placement-aware plans can also reduce how much data you need to move in the first place.
Rebalancing Strategies and Tradeoffs
This table compares common ways systems move data back into balance after a change or failure. Use it to pick the right approach based on your latency targets, how fast you scale, and how much background traffic your cluster can handle.
| Strategy | What it optimizes | What can go wrong | Best fit |
|---|---|---|---|
| “As fast as possible” movement | Shortest time to evenness | p99 spikes and app slowdowns | Maintenance windows |
| Throttled background movement | Steadier app latency | Longer time in a skewed state | Shared clusters with SLOs |
| Placement-aware balancing | Less data to move | Poor rules can trap imbalance | Large clusters with many racks |
| Incremental scale changes | Predictable change control | Slower expansions | Frequent capacity growth |
Achieving Predictable Storage Rebalancing with Simplyblock
Simplyblock runs online, automated rebalancing as part of its scale-out model, so the cluster can spread data and load as you add nodes and drives.
The key outcome is control. Rebalancing should not surprise the apps. Simplyblock also calls out that distributed rebalancing kicks in after drive or node failures and during expansions, with a focus on keeping latency and throughput consistent across the cluster.
Storage Rebalancing Improvements to Watch
Teams now expect “always on” movement with fewer side effects. Vendors and open-source systems keep improving pacing, observability, and placement logic so clusters can heal and scale without brutal performance dips.
Ceph’s balancer work shows how much attention large fleets put into automated balancing and supervised modes.
Related Terms
Teams often review these glossary pages alongside Storage Rebalancing when they design placement rules, recovery behavior, and stable performance in shared clusters.
Questions and Answers
Storage rebalancing redistributes data evenly across nodes or disks to avoid hotspots and I/O contention. This improves IOPS and throughput, ensuring balanced performance for cloud-native applications.
Storage rebalancing is critical after scaling storage nodes or adding new drives. It ensures that persistent volumes are evenly distributed, helping maintain predictable performance in dynamic Kubernetes clusters.
Yes, it can if not managed properly. Modern systems use background or throttled rebalancing to minimize disruption, especially in software-defined storage environments handling live workloads.
In NVMe/TCP setups, rebalancing involves shifting namespaces or volumes across targets. This requires awareness of latency, bandwidth, and topology to maintain optimal access paths during and after rebalancing.
Yes, DPUs can offload rebalancing logic and data movement from the CPU, speeding up redistribution while reducing host load. This is especially valuable in performance-sensitive storage systems using NVMe or hybrid workloads.