Storage Resiliency vs Performance Tradeoffs
Terms related to simplyblock
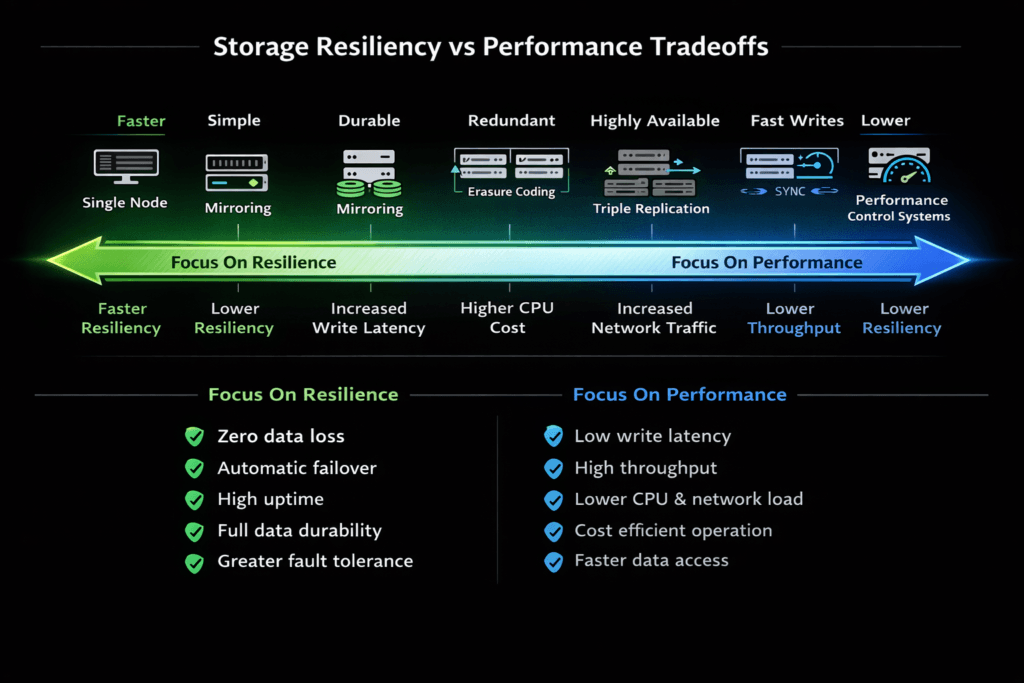
Storage Resiliency vs Performance Tradeoffs describes the tension between stronger data protection and faster I/O. When you raise resiliency, the system does more work per write. When you push for speed, you often accept a bigger risk window or fewer safe failure options.
Executives see this tradeoff as risk, cost, and customer impact. Platform teams see it as p99 latency, rebuild pressure, and noisy-neighbor behavior. In Kubernetes Storage, the balance matters more because many stateful apps share the same cluster, and storage spikes spread fast. A Software-defined Block Storage platform helps because you can set different protection and QoS rules per workload instead of forcing one global setting.
Why Protection Adds Cost to Every I/O
Resiliency needs redundancy. Redundancy increases write traffic, metadata work, and network movement. Those costs show up as higher commit latency, lower steady throughput, or both.
Performance needs short paths and stable queues. Short paths cut CPU overhead. Stable queues keep tail latency under control. If the storage layer runs “extra steps” on each write, it can raise jitter, especially under load.
Failure handling drives the real outcomes. Rebuild and rebalance to create background traffic. That traffic competes with production reads and writes. Without firm limits and priorities, the cluster stays “up,” but apps still time out.
🚀 Balance Resiliency and Performance for Stateful Apps, Natively in Kubernetes
Use Simplyblock to raise durability without sacrificing NVMe/TCP latency at scale.
👉 Use Simplyblock for Multi-Tenant QoS and Resilient Storage →
Storage Resiliency vs Performance Tradeoffs in Kubernetes Storage
Kubernetes changes how you apply resiliency. Pods move, nodes roll, and scaling events happen often. Storage must keep volumes available while the cluster changes around it.
Start by mapping storage policy to workload needs. Databases usually need strict durability and stable p99 latency. Event logs often value sustained write throughput. Caches can trade durability for speed. When you treat all apps the same, you either overspend on protection or underdeliver on performance.
Also, plan for the recovery path. Fast failover helps, but a rebuild can still hurt users if it floods the network or saturates the CPU. Good operations set rebuild priorities, cap background rates during peak hours, and enforce per-tenant QoS so one team does not break everyone else.
Storage Resiliency vs Performance Tradeoffs and NVMe/TCP
NVMe/TCP makes high-performance networking practical on standard Ethernet, which helps teams scale without niche fabric work. It also fits disaggregated designs that isolate storage services from application nodes, which can reduce cross-talk during spikes.
Protocol speed does not remove resiliency overhead. Replication multiplies write fan-out. Erasure coding adds parity compute and extra traffic during repair. The win comes from efficiency in the data path. Efficient I/O handling keeps CPU headroom available for protection features, and it keeps tail latency steadier when the cluster heals.
How to Measure the Tradeoff Without Guesswork
Benchmarking this topic takes more than a peak IOPS chart. You need to see what happens during change.
Run a steady read/write profile first. Keep it running while you expand capacity, add nodes, or change protection level. Then inject a fault, such as a node restart or a drive loss, and measure the impact during heal. Track p95 and p99 latency, throughput, and the time to return to baseline.
Test at different fill levels. Many systems behave well at low utilization. Many systems struggle when pools run hot. Your decision should rely on the “busy” results, not the “empty” results.
Controls That Shift the Balance in Your Favor
- Pick replication when you want simpler failure behavior and faster rebuilds, and pick erasure coding when you want better usable capacity at scale.
- Enforce QoS so rebuild and rebalance cannot consume the entire latency budget.
- Define failure domains clearly so copies do not land in the same rack, zone, or power path.
- Keep CPU headroom for parity, checksums, and encryption, especially for heavy writes.
- Test peak load plus recovery, because real incidents rarely wait for quiet hours.
Comparison – Protection Methods Versus Speed
This table shows the typical effect of common resiliency choices on latency, repair behavior, and Kubernetes fit.
| Approach | Resiliency strength | Typical performance cost | Recovery profile | Best fit |
|---|---|---|---|---|
| 2×–3× replication | High | More write traffic | Faster, simpler rebuild | Databases, hot tiers |
| Erasure coding | High (with enough parity) | More compute and network on writes | Repairs can take longer | Capacity tiers, large pools |
| Hybrid tiers | High | Fast hot path, efficient cold path | Balanced repair costs | Mixed workloads |
| Minimal protection | Low–Medium | Lowest overhead | Highest risk | Caches, short-lived data |
Storage Resiliency vs Performance Tradeoffs with Simplyblock™
Simplyblock™ focuses on Software-defined Block Storage for Kubernetes Storage, with NVMe-first design and policy-driven controls. Teams can set per-volume durability and QoS so critical workloads keep stable latency while the platform handles background work. That matters because most “downtime” starts as a latency problem.
Its SPDK-based, user-space data path reduces overhead and improves CPU efficiency. That extra headroom helps when you raise protection levels, because replication, parity, and checksums all consume resources. With NVMe/TCP support, simplyblock also scales out on standard Ethernet while keeping performance behavior consistent during growth and recovery.
What Changes Next for Resiliency and Speed
Platforms will keep moving toward policy-driven behavior. Teams will define SLOs, protection targets, and recovery priorities as code, then enforce them automatically during failure and scale events.
More storage work will shift to DPUs and IPUs to reduce CPU jitter and isolate storage processing from app spikes. Hybrid protection will also grow because it keeps hot paths fast while improving usable capacity for colder data. These shifts raise the bar for tail-latency control during rebuild, not just “good numbers” on a clean test.
Related Terms
Teams reference these related terms when balancing durability and speed in Kubernetes storage designs.
Storage Latency vs Throughput
p99 Storage Latency
Storage Quality of Service (QoS)
Scale-Out Storage Architecture
Questions and Answers
Increasing resiliency through replication or erasure coding adds write overhead and latency. Synchronous replication requires data to be written to multiple nodes before acknowledgment, which can slightly reduce throughput. Modern platforms using distributed block storage architecture minimize this tradeoff with optimized data paths.
Yes, synchronous replication introduces additional network and write latency because data must be committed to multiple replicas. However, systems built on NVMe over TCP can maintain low latency while preserving strong consistency guarantees.
Balancing performance and resiliency requires workload-aware tuning. Critical databases may require full replication, while less sensitive workloads can use lower redundancy levels. Simplyblock enables flexible policies within its software-defined storage platform to match performance needs with durability goals.
Erasure coding reduces storage overhead but can increase CPU usage and rebuild time. Replication is typically faster for write-heavy workloads. Choosing the right model depends on application requirements and the underlying scale-out storage architecture.
Simplyblock combines distributed NVMe storage with efficient replication and direct data paths. Its Kubernetes-native storage integration ensures high availability while maintaining low-latency I/O for production workloads.