Erasure Coding
Terms related to simplyblock
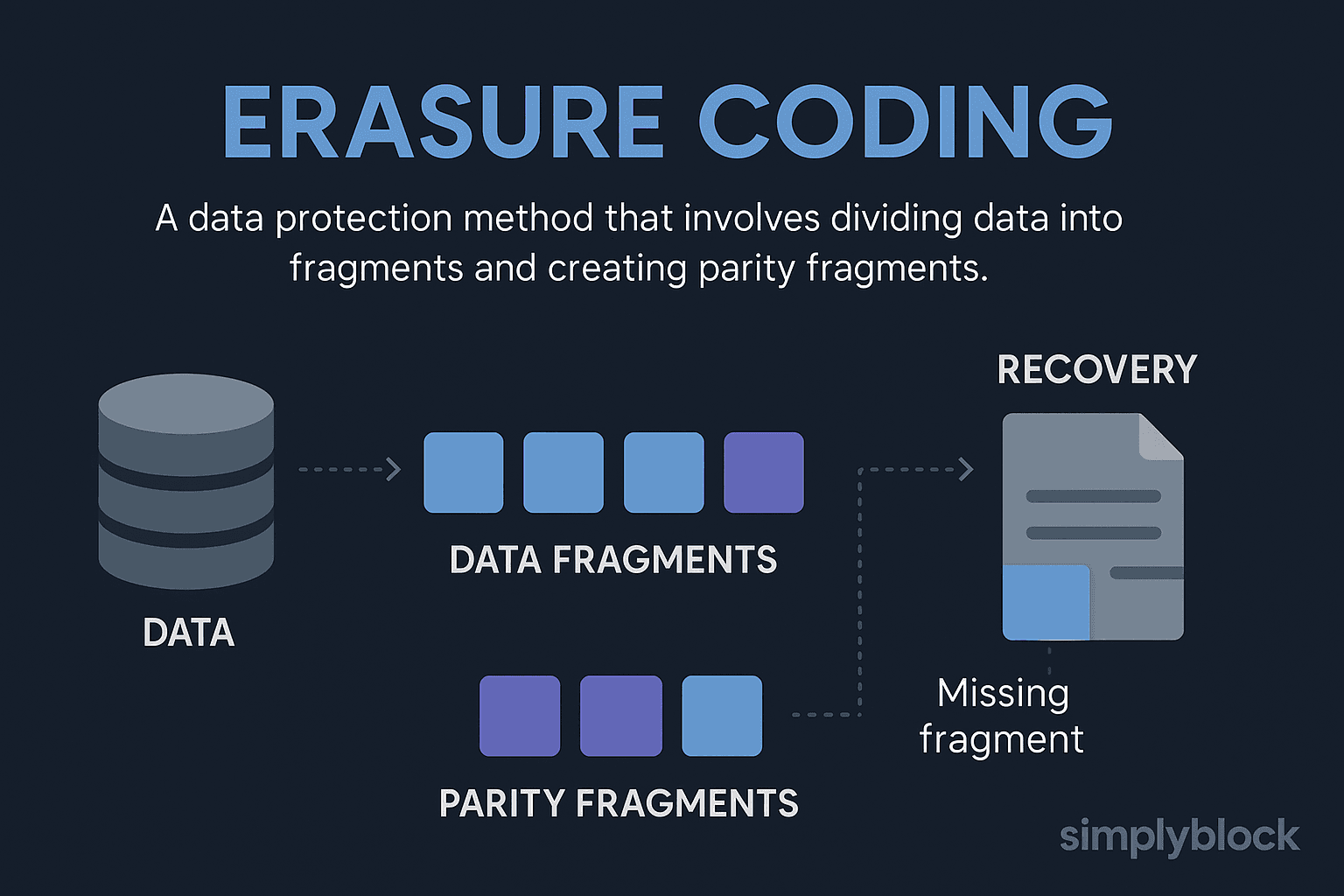
Erasure coding is a method of data protection that breaks data into fragments, expands it with redundant pieces using mathematical algorithms, and distributes it across different nodes or storage devices. This approach ensures fault tolerance and storage efficiency, especially in distributed and cloud-native environments.
Unlike traditional RAID or full replication, erasure coding can tolerate multiple simultaneous failures while using significantly less storage overhead. In simplyblock, erasure coding is a core part of its resilient, scale-out block storage, enabling high availability and reduced cost per GB.
How Erasure Coding Works
At its core, erasure coding uses two parameters: k and m.
- k = number of original data fragments
- m = number of parity fragments (redundancy)
Together, they form a (k+m) scheme. For example, a 6+3 configuration splits data into 6 parts and adds 3 parity blocks. Any 6 out of the 9 total blocks are sufficient to reconstruct the full data set, allowing the system to tolerate up to 3 failures.
This model is widely used in object stores, distributed filesystems, and Kubernetes-native block storage platforms.
Benefits of Erasure Coding
Erasure coding delivers a unique combination of resiliency and efficiency, especially compared to legacy RAID or replication-based systems:
- Higher fault tolerance: Can withstand multiple simultaneous node or disk failures.
- Efficient storage utilization: Achieves similar protection to 3x replication with up to 50% less overhead.
- Ideal for scale-out architectures: Works seamlessly in multi-node, distributed environments.
- Durable and reliable: Ensures long-term data integrity for large datasets.
- Cloud-native compatibility: Works across on-prem, cloud, and hybrid deployments.
In simplyblock, erasure coding is integrated directly into the storage backend, supporting seamless recovery and elastic scaling across zones.
Use Cases for Erasure Coding
Erasure coding is widely adopted in storage architectures where capacity, reliability, and scale must be balanced:
- Object storage systems like MinIO, Ceph, or AWS S3
- Kubernetes persistent volumes with distributed storage backends
- Cloud-native backup and archival systems
- High-density storage nodes in edge deployments
- Databases and analytics platforms requiring petabyte-scale durability
Erasure coding also complements snapshotting and multi-tenant QoS systems for efficient, resilient enterprise storage.
Erasure Coding vs Replication vs RAID
Here’s how erasure coding compares with other fault-tolerance techniques:
| Feature | Erasure Coding | Replication | RAID (5/6/10) |
|---|---|---|---|
| Storage Efficiency | High (up to 66%+) | Low (2x–3x data footprint) | Moderate to low |
| Failure Tolerance | Customizable (n-of-m) | 1 or 2 nodes max | 1 or 2 disks max |
| Scalability | High, node-level | Moderate | Limited to local disks |
| Rebuild Speed | Parallelized, distributed | Fast (full copy) | Slow in large RAID groups |
| Cloud-native Ready | Yes | Yes | No |
Erasure Coding in Simplyblock™
Simplyblock implements adaptive erasure coding as part of its scale-out, MAUS architecture:
- Configurable protection policies (e.g., 6+3, 10+4)
- Efficient block-level redundancy with no replica waste
- Works across zones, regions, and clouds
- Integrated with NVMe-over-TCP for high throughput
- Fully compatible with CSI volumes and Kubernetes-native workloads
You can try out different erasure coding configurations with the erasure coding calculator.
Related Terms
Teams often review these glossary pages alongside Erasure Coding when they set durability targets, map failure domains, and keep Kubernetes Storage predictable on Software-defined Block Storage over NVMe/TCP.
CRUSH Maps
Fault Tolerance
Storage High Availability
RAID
External Resources
- What is Erasure Coding – Wikipedia
- Data Protection in Ceph – Ceph Docs
- Erasure Coding vs Replication – MinIO
- AWS S3 Storage Classes Explained
- Designing Resilient Storage Systems – Red Hat
Questions and Answers
Erasure coding is a data protection method that breaks data into fragments, encodes it with redundancy, and distributes it across multiple storage nodes. It enables fault tolerance with less storage overhead compared to traditional replication, making it ideal for scalable, resilient infrastructure.
Erasure coding uses mathematical parity to rebuild lost data, offering the same level of protection as replication with significantly lower storage costs. While replication is faster for recovery, erasure coding is more space-efficient, especially in software-defined storage systems.
Yes, when implemented at the storage layer, erasure coding can provide efficient redundancy for Kubernetes-native storage. It helps reduce overhead in stateful applications while ensuring data durability across nodes.
Yes, encoding and decoding add CPU and I/O overhead, especially in write-heavy workloads. However, pairing erasure coding with high-throughput NVMe over TCP storage helps minimize latency while maintaining resilience.
Absolutely. Encryption at rest can be applied to each fragment before or after encoding. When paired with key isolation, this ensures that erasure-coded data remains secure and compliant in multi-tenant environments.