Storage Tiering
Terms related to simplyblock
Storage tiering is a data management strategy that classifies and moves data between different types of storage media based on performance, cost, and access frequency. The goal is to optimize both cost and performance by storing hot (frequently accessed) data on high-speed storage like NVMe SSDs and cold (rarely accessed) data on slower, cost-efficient media like HDDs or cloud archives.
Tiering can be manual or automated, and is often a core feature in software-defined storage platforms such as simplyblock, where intelligent tiering logic moves data in real time based on workload behavior.
How Storage Tiering Works
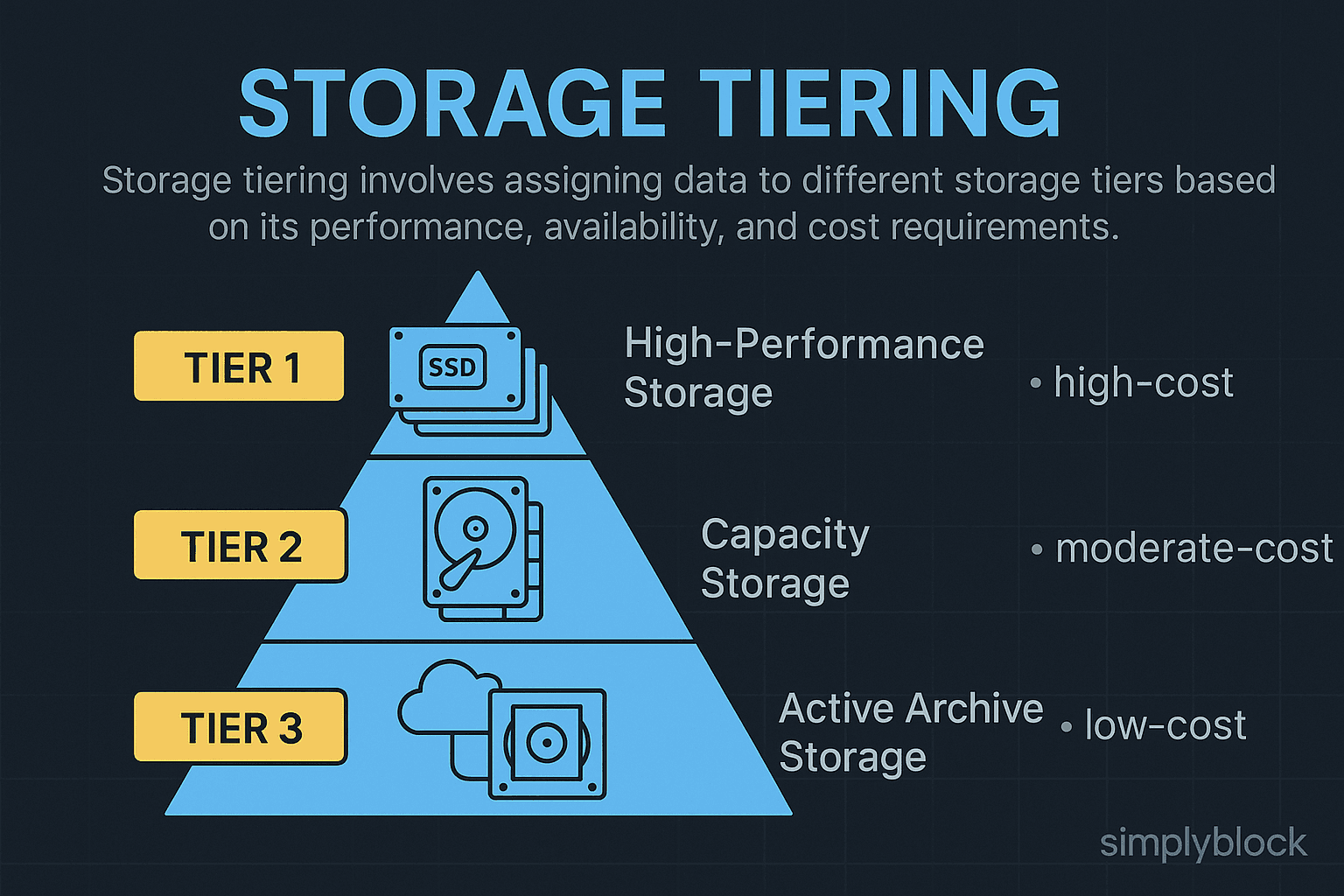
Storage systems assign data to different tiers based on rules or real-time analytics. Common tiers include:
- Tier 0: NVMe SSDs for ultra-low latency
- Tier 1: SATA SSDs for general-purpose workloads
- Tier 2: HDD arrays for archival or backup
- Tier 3: Cloud object storage (e.g., S3 Glacier) for long-term retention
Tiering can occur at the file, block, or object level. In block-based systems like simplyblock, tiering is handled automatically at the block level to avoid performance bottlenecks.
Benefits of Storage Tiering
Implementing storage tiering brings significant operational and financial advantages:
- Cost efficiency: High-performance storage is used only where needed, while cold data is moved to cheaper media.
- Performance optimization: Critical applications benefit from NVMe speed, while infrequently used data doesn’t consume premium IOPS.
- Scalability: Supports growing datasets across multiple mediums without re-architecting.
- Improved SLAs: Aligns data placement with performance policies or service-level objectives.
- Resource utilization: Minimizes overprovisioning and reduces storage sprawl.
In multi-tenant environments, tiering also supports differentiated storage plans with varied QoS policies, backed by platforms like simplyblock’s multi-tenancy features.
Common Use Cases for Storage Tiering
- Database platforms: Keep indexes and active partitions on NVMe; archive old partitions on HDD.
- Virtualized environments: Assign VMs based on their performance profile.
- Cloud-native pipelines: Automatically offload logs, backups, and staging datasets to lower tiers.
- Edge deployments: Optimize small-form storage footprints with dynamic tiering.
- Regulatory compliance: Migrate older data to long-term storage while maintaining retention policies.
Storage Tiering vs Caching vs Archiving
Tiering is often confused with similar strategies like caching or archiving. Here’s how they differ:
| Feature | Storage Tiering | Caching | Archiving |
|---|---|---|---|
| Purpose | Balance performance/cost | Accelerate read/write speed | Retain inactive data long-term |
| Data Movement | Multi-directional | Frequently accessed data only | One-time migration |
| Data Type | Active and semi-active | Hot data only | Cold/inactive data |
| Media Types | SSD, HDD, cloud tiers | DRAM, NVMe, SSD | HDD, tape, cold cloud |
| User Access | Transparent | Transparent | May require manual restore |
Storage Tiering in Simplyblock™
Simplyblock enables block-level adaptive tiering across NVMe SSDs and future-integrated tiers like HDD or object stores. Key features include:
- Real-time telemetry-driven tiering
- Dynamic movement of data between fast and capacity nodes
- NVMe-first design ensures low-latency performance for hot data
- Seamless integration with erasure coding for durability
- Integration with CSI-based Kubernetes deployments via NVMe-over-TCP volumes
The result is efficient, cloud-native storage infrastructure that dynamically adjusts to workload demand without manual tuning.
Related Terms
Teams often review these glossary pages alongside Storage Tiering when they define hot-data placement, cold-capacity targets, and performance guardrails across mixed media.
Hot vs Cold Data
Cold Storage Tier
Storage Quality of Service (QoS)
TCO (Total Cost of Ownership)
External Resources
- Automated Storage Tiering – IBM
- What is Storage Tiering – TechTarget
- AWS S3 Storage Classes
- Kubernetes Volume Management – Official Docs
- Block-Level Tiering – Oracle
Questions and Answers
Storage tiering optimizes performance and cost by automatically moving data between high-speed and lower-cost storage layers. Frequently accessed data stays on fast media like NVMe, while cold data moves to slower, cheaper tiers—perfect for balancing performance with budget.
In Kubernetes, storage tiering is implemented through Container Storage Interface (CSI) and storage class definitions. Platforms like Simplyblock can dynamically provision high-performance NVMe over TCP volumes while offloading inactive data to lower tiers.
Storage tiering reduces cloud spend by keeping only hot data on premium storage. Cold or infrequently accessed data can be moved to cheaper tiers, aligning with cloud storage optimization goals and long-term retention strategies.
Only cold data stored on lower-performance media may experience slower access times. Hot data remains on fast NVMe or SSD tiers, ensuring mission-critical applications retain high-speed performance. Intelligent tiering keeps this balance optimized in real-time.
Yes, especially when combined with encryption at rest. Each volume tier can maintain encryption and tenant isolation, ensuring security even as data moves between fast and archival storage layers.