Write Amplification
Terms related to simplyblock
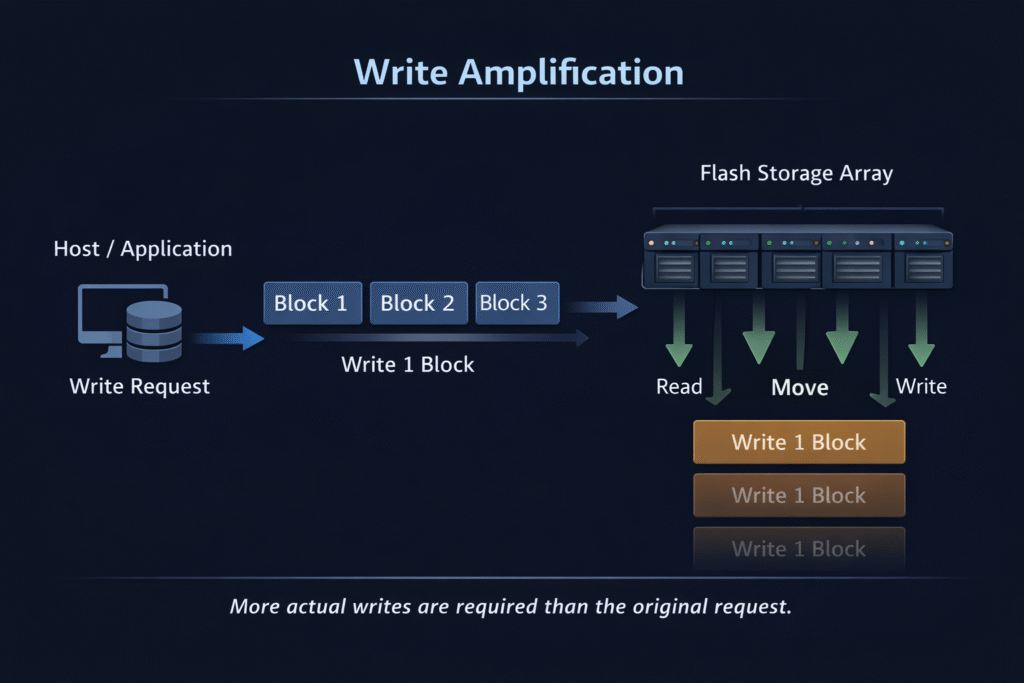
Write Amplification describes how many physical bytes an SSD writes internally compared to the bytes your host sends. If the host writes 1 GB and the SSD programs 3 GB of NAND, the write amplification factor (WAF) equals 3. WAF matters because it drives SSD endurance (TBW/DWPD), tail latency during garbage collection, and the real cost per usable terabyte in busy clusters.
Most teams see WAF climb when random overwrites, snapshot deltas, replication logs, and metadata churn collide with how NAND flash works. The SSD’s flash translation layer (FTL) remaps updates and runs garbage collection, so “small” host writes can trigger larger internal data movement.
Optimizing Write Amplification with Modern Solutions
Flash-friendly platforms reduce extra rewrites by shaping I/O, limiting background churn, and avoiding copy-heavy data paths. Software-defined Block Storage helps because it puts those controls in software, rather than locking them into array firmware. When the storage layer manages snapshots, replication, and rebuild behavior with clear policies, you can keep WAF stable as workloads and tenants change.
A practical goal for executives: target predictable p95/p99 latency while keeping SSD write budgets within warranty targets. That goal usually requires workload isolation, policy-driven protection, and a storage engine that minimizes internal copies.
🚀 Reduce Write Amplification with Copy-on-Write Storage Paths
Use Simplyblock to cut extra writes, extend SSD life, and stabilize p99 latency with NVMe/TCP Kubernetes Storage and Software-defined Block Storage.
👉 See How Copy-on-Write Impacts Write Amplification →
Write Amplification in Kubernetes Storage
Kubernetes Storage adds layers that can raise WAF even when the underlying media looks healthy. Container filesystems, CSI behavior, snapshots, and frequent rescheduling all change the write pattern. Many stateful apps also write small blocks, update logs often, and rotate data aggressively, which can amplify internal writes.
Kubernetes Persistent Volumes and StorageClasses give you portability, but they also hide important details like filesystem choice, mount options, and snapshot strategy. Teams should treat these knobs as part of the storage contract, especially for databases, queues, and observability stacks.
Write Amplification and NVMe/TCP
NVMe/TCP supports disaggregated architectures that scale storage pools over standard Ethernet and reduce the need for “write hot spots” on compute-local drives. The protocol does not reduce WAF on its own, but it enables designs where the storage layer can steer writes, control background work, and keep performance predictable as clusters grow.
In a SAN alternative rollout, NVMe/TCP also simplifies network operations compared to RDMA-only approaches while still delivering high IOPS and low latency when the storage engine keeps overhead low.
Measuring and Benchmarking Write Amplification Performance
Start with a workload definition that matches production: block size, read/write mix, randomness, queue depth, and a run long enough to reach steady state. fio remains the common tool for repeatable I/O generation, and it lets you lock job parameters so teams can compare results across releases and hardware.
To compute WAF, compare host bytes written against NAND bytes written from SMART or vendor telemetry when the drive exposes it. Pair that value with p95/p99 latency, not just average throughput. For Kubernetes Storage, benchmark from inside a pod and at the volume layer to catch hidden amplification from snapshots, filesystem journaling, and metadata-heavy control-plane activity.
Approaches for Improving Write Amplification Performance
Use WAF as a control metric, then apply changes that reduce rewrites and smooth background work:
- Keep steady free space (or explicit overprovisioning) so garbage collection does less data movement under load.
- Prefer append-friendly write patterns for log-heavy services, and avoid small random overwrites when the app can batch.
- Align filesystem, block size, and discard/TRIM behavior to reduce stale-page buildup and metadata churn.
- Set snapshot and clone policies that limit delta sprawl and avoid copy-heavy retention for busy volumes.
- Enforce multi-tenant QoS so one tenant’s compaction or rebuild activity does not inflate WAF for the entire cluster.
- Use NVMe/TCP-based disaggregation when local disks create uneven wear and unpredictable write pressure across nodes.
- Choose Software-defined Block Storage that uses efficient datapaths (for example, SPDK-style user-space I/O) to reduce CPU overhead and extra copies.
Comparing Write Amplification Risk in Common Storage Patterns
Different storage designs trigger different write patterns and background behaviors. This table summarizes where teams usually see extra internal writes and how that impacts predictable performance.
| Storage approach | Typical WAF drivers | What happens at p99 | Best fit |
|---|---|---|---|
| Local SSD on each worker | Random overwrites, filesystem journaling, GC under low free space | Fast until steady state, then spikes during GC | Small clusters, single-tenant, edge |
| Legacy SAN | Controller caching behavior, rebuild workflows, protocol overhead | Often stable for basic loads, less efficient for modern mixed I/O | Legacy VM estates, conservative change control |
| Generic distributed storage | Replication writes, metadata chatter, rebalance/recovery churn | Tail latency jumps during recovery and rebalancing | Capacity pooling where cost matters most |
| NVMe/TCP + Software-defined Block Storage | Policy-driven background work, reduced copies, workload isolation | More stable p95/p99 and better endurance when tuned | Kubernetes Storage, SAN alternative, multi-tenant platforms |
Predictable Write Amplification Control with Simplyblock™
Simplyblock™ keeps write amplification predictable by tightening the write path and managing background work at the storage layer. With CSI-based Kubernetes integration, platform teams standardize provisioning and still enforce multi-tenancy and QoS to curb noisy-neighbor effects.
Its NVMe/TCP architecture scales as a SAN alternative on standard Ethernet. This design pools flash, limits uneven wear, and stabilizes tail latency under mixed workloads. In hyper-converged, disaggregated, or hybrid setups, the same Kubernetes Storage control plane and Software-defined Block Storage policies stay consistent across environments.
What’s Next for Write Amplification Control
Storage stacks will keep pushing toward fewer copies and more predictable write paths. User-space I/O frameworks such as SPDK reduce kernel overhead and can help stabilize latency during heavy write pressure.
DPUs and IPUs also move storage and networking work off the host CPU, which helps teams sustain high concurrency without adding jitter from shared compute. At the spec level, NVMe continues to evolve across command sets and transports, including TCP, which supports broader NVMe-oF adoption and makes disaggregated flash pools easier to operate.
Related Terms
Teams often review these glossary pages alongside Write Amplification when they tune Kubernetes Storage and Software-defined Block Storage for steady p99 performance.
Zero-copy I/O
Tail Latency
NVMe
Persistent Storage
NVMe SSD Endurance
Write Coalescing
Questions and Answers
Write amplification increases the actual amount of data written to storage compared to what applications request. In Kubernetes stateful workloads, high write amplification can reduce SSD lifespan and degrade performance over time.
It typically results from small random writes, garbage collection, and frequent overwrites. Without careful block management—as in some software-defined storage solutions—this overhead can grow significantly.
Using NVMe over TCP with large, sequential I/O and optimized storage drivers helps reduce write amplification. Proper alignment and avoiding unnecessary data copies are also key strategies.
Yes. Higher write amplification shortens SSD lifespan, increasing replacement costs. Managing it effectively is crucial for long-term cloud cost optimization in persistent storage infrastructure.
Thin clones and snapshots can increase write amplification when heavily modified, as they depend on copy-on-write mechanisms. Monitoring I/O patterns is essential to avoid unexpected write overhead.