Zonal vs Regional Storage
Terms related to simplyblock
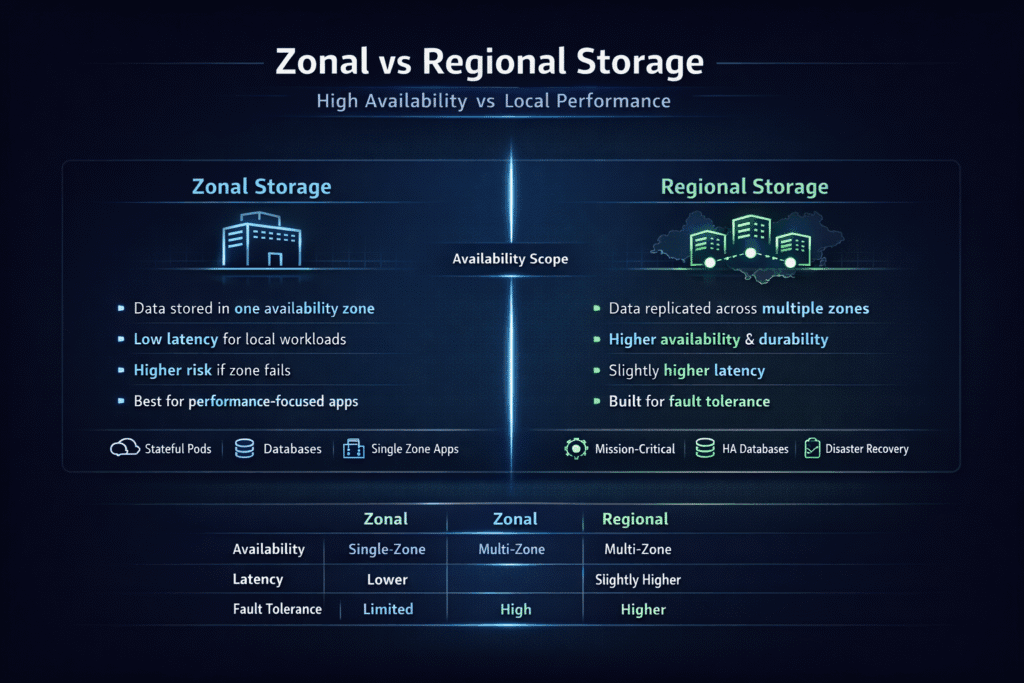
Zonal storage keeps a volume in one availability zone. Regional storage keeps the same data across multiple zones inside one region, so a single-zone outage does not automatically take the volume down. Cloud providers implement this differently, but the decision stays the same: zonal options often win on simplicity and cost, while regional options win on zone-level resilience.
This choice matters most for stateful apps. A service can restart quickly, but a volume that can’t attach in the right place turns a restart into downtime.
How Zonal and Multi-Zone Replication Differ in Practice
Zonal storage ties your data to one zone. That makes placement clear and keeps the network path short when the compute runs in the same zone.
Regional storage copies writes across zones (provider-specific). Google Cloud describes Regional Persistent Disk as storage replicated between two zones in the same region. Azure documents zone-redundant disk options that replicate across availability zones in a region. AWS commonly uses EFS Regional for multi-AZ access, since EFS stores data redundantly across multiple AZs in a region.
🚀 Choose the Right Zonal vs Regional Storage Model, Natively in Kubernetes
Use Simplyblock to run NVMe/TCP storage through CSI with zone-independent volumes—so stateful pods reschedule across zones without attachment failures.
👉 Use Simplyblock for Multi-Zone Kubernetes Storage →
Zonal vs Regional Storage in Kubernetes Clusters
Kubernetes turns this into scheduling rules. With a zonal volume, Kubernetes must place the Pod in the same zone, or the attachment will fail. That can block reschedules during drains if the cluster runs out of matching capacity.
Regional storage can reduce that pressure because the data stays available across zones (depending on the backend). Even then, the cluster still needs good topology behavior so it provisions storage in the right place. “Wait for first consumer” helps here: Kubernetes chooses a node first, then provisions the volume to match that placement.
NVMe/TCP Impacts on Latency, Throughput, and Replication Cost
Zonal designs often feel faster because they keep traffic inside one zone and avoid cross-zone hops. Regional designs can add overhead under write load, because replication takes work and can show up as higher tail latency during busy periods.
NVMe/TCP won’t erase those tradeoffs, but it gives you a clean, standards-based data path over Ethernet. The bigger win comes from keeping the path predictable and controlling background work (resync, rebuild, snapshot traffic) so p99 stays steady.
How to Benchmark Availability Choices Under Load and Failover
Benchmark with the failure domain in mind. A zonal option can look perfect until you simulate a zone disruption or a drain wave.
Measure reschedule and reattach time, p95/p99 latency during peak load, and how performance changes while the system replicates or rebuilds. Also, run a mixed test where your normal workload stays steady while you trigger a drain, a snapshot burst, or a restore job. This exposes the real “cost” of replication and recovery, not just the best-case numbers.
Simple Rules for Picking the Right Model
- Choose zonal when you want the simplest setup, and you can tolerate a zone event through app-level failover, restore, or re-create patterns.
- Choose regional when a zonal outage must not take the volume offline, and you need lower RPO/RTO inside one region.
- Stick with zonal for ultra-low-latency tiers where cross-zone replication overhead would hurt the hot path.
- Use regional for shared services (core databases, metadata stores, control-plane data) that need stronger availability.
- Re-check price and limits per service, because providers price and cap zonal vs regional differently.
Zonal and Regional Storage Tradeoffs in One Table
This table summarizes the practical differences teams see when they design for one zone versus multiple zones. It also shows where Kubernetes scheduling and recovery can get easier—or harder—based on the storage choice.
| Dimension | Zonal storage | Regional storage |
|---|---|---|
| Failure domain | One zone | Multiple zones in one region |
| Typical goal | Lowest complexity and cost | Higher availability inside a region |
| Performance feel | Often lower jitter when compute matches zone | Can add replication overhead under write load |
| Kubernetes impact | Pod must land in the same zone as the volume | More flexible reschedules (backend-dependent) |
| Best fit | Single-zone apps, cost-first tiers | HA stateful tiers, stricter RPO/RTO targets |
Simplyblock for Multi-Zone Storage – Predictable Performance at Scale
When teams compare zonal and regional models, they usually want two things: steady performance and simpler operations. Simplyblock targets that with Kubernetes-native storage via CSI and NVMe/TCP-based volumes for I/O-heavy workloads.
For managed Kubernetes, Simplyblock also positions itself for multi-zone environments like GKE regional clusters and multi-zonal scaling, which helps teams keep storage behavior consistent as node pools grow and shift.
What to Watch Next in Cloud Availability Options
Cloud storage keeps moving toward clearer availability controls: more zone-redundant options, better automation, and tighter ties to schedulers. Azure continues to expand guidance on disk redundancy, while GCP keeps pushing regional block options for HA designs.
As these features mature, the best choice will depend less on labels and more on how your stack behaves under load, rebuilds, and real recovery drills.
Related Terms
Teams often review these glossary pages alongside Zonal vs Regional Storage when they set durability targets, plan for zone failures, and define recovery expectations.
- Storage High Availability
- RPO (Recovery Point Objective)
- RTO (Recovery Time Objective)
- Fault Tolerance
- Region vs Availability Zone
Questions and Answers
Zonal storage stores data in a single availability zone, offering low latency and cost. Regional storage replicates data across multiple zones, increasing durability. Regional options are ideal for high-availability Kubernetes workloads.
Use zonal storage for latency-sensitive apps where downtime is acceptable. Choose regional storage for mission-critical workloads that need zone failure tolerance, especially in production clusters.
Yes, regional storage may introduce slightly higher latency due to cross-zone replication. However, modern software-defined storage platforms minimize this with smart caching and optimized data paths.
Yes. NVMe over TCP enables fast block storage access across zones, making it suitable for regional deployments that need both performance and high availability without specialized networking.
Zonal storage is cheaper but less resilient. Regional storage costs more due to replication, but supports cloud cost optimization long-term by reducing downtime risk and improving SLA compliance.