Dynamic Volume Provisioning
Terms related to simplyblock
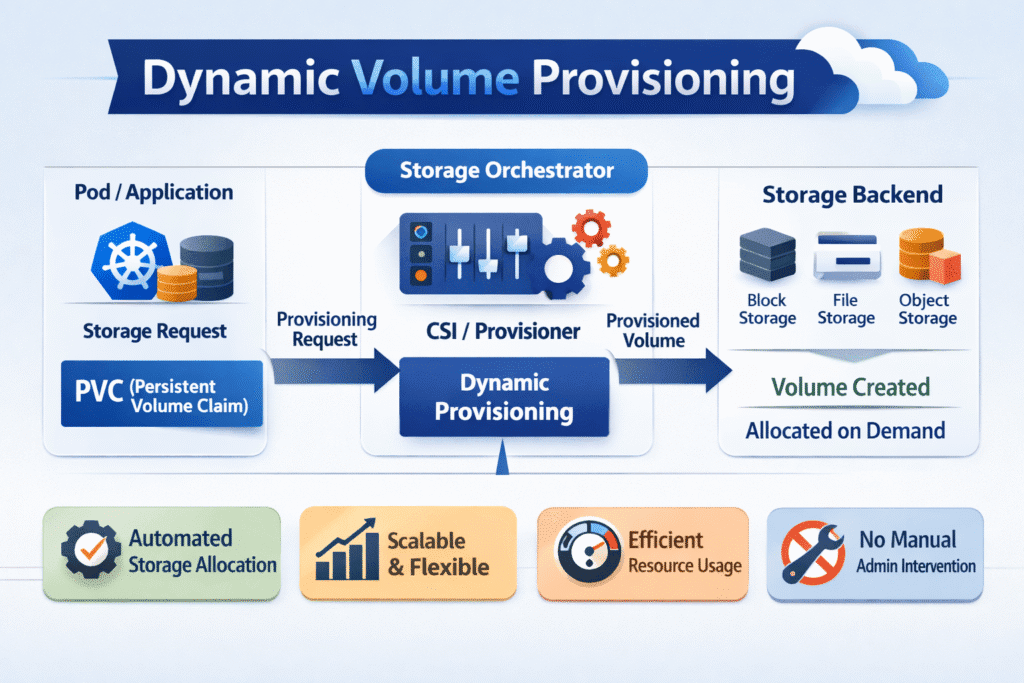
Dynamic Volume Provisioning creates storage volumes automatically when an app requests them. Kubernetes triggers this flow when a developer applies a PersistentVolumeClaim (PVC). A StorageClass tells Kubernetes which provisioner to call and what policy to apply. Kubernetes then creates and binds a PersistentVolume (PV) that matches the claim.
Executives value this model because it removes ticket queues and reduces time-to-delivery for stateful services. Platform teams value it because they can standardize policy, enforce guardrails, and keep Kubernetes Storage consistent across clusters.
Making On-Demand Storage a Default Without Surprises
Dynamic provisioning works best when it behaves like a platform contract. App teams should request capacity and basic access mode. Platform teams should own the policy surface area, including performance tier, protection behavior, and reclaim rules.
This is where Software-defined Block Storage helps. A software-defined layer can map each StorageClass to a real backend policy and keep that mapping steady across baremetal and virtual fleets. It also helps when you need multi-tenant controls and predictable tail latency under load.
🚀 Automate Dynamic Volume Provisioning with CSI for Stateful Workloads
Use simplyblock to create NVMe/TCP volumes on demand, keep StorageClass policy consistent, and reduce PV ops friction.
👉 Use simplyblock for NVMe/TCP Kubernetes Storage →
Dynamic Volume Provisioning Workflows in Kubernetes Storage
Dynamic Volume Provisioning depends on Kubernetes controllers plus a CSI-compatible backend. The cluster does not guess what storage to create. It follows StorageClass fields such as provisioner, parameters, reclaimPolicy, and volumeBindingMode.
Two design choices shape outcomes. Topology-aware provisioning reduces wrong-zone volumes by aligning PV creation with scheduling choices. Many teams pair that with “wait for first consumer,” so the cluster picks a node first, then provisions the volume that matches that placement.
Lifecycle automation matters as much as initial creation. Resize, snapshot, clone, and delete all ride the same contract. When a step fails, manual work piles up fast.
Dynamic Volume Provisioning with NVMe/TCP Backends
Dynamic Volume Provisioning does not guarantee performance. It guarantees automation. Performance comes from the data path, isolation controls, and backend efficiency.
NVMe/TCP matters because it delivers NVMe-oF semantics over standard Ethernet. Teams often choose it as a SAN alternative for disaggregated Kubernetes Storage, especially when they want high IOPS without RDMA-only requirements across the whole fabric.
For high-churn environments, the control plane and the data plane both matter. A fast create path that mounts slowly still delays pods. A fast mount path that suffers noisy-neighbor contention still breaks p99 latency. A backend that keeps CPU overhead low helps protect both outcomes, especially on dense nodes.
Benchmarking Dynamic Volume Provisioning at Scale
Measure the workflow, not just raw throughput. Track time from PVC create to PV bound, time from pod schedule to mount complete, and error rates for provision and delete operations. These numbers show whether the platform can keep up with rollouts and autoscaling.
Then correlate workflow timing with workload signals. Watch p95 and p99 latency, plus node CPU during peak I/O. Include a churn test that runs provisioning while the cluster performs a rolling update. This approach shows where lifecycle timing slows down under pressure.
Reducing Provisioning Delays and Operational Noise
Use a small set of rules, and apply them every time you add a new StorageClass or backend. This is the only list on the page.
- Keep StorageClass tiers limited, and map each tier to clear performance and protection behavior.
- Use topology-aware binding rules so volumes land where workloads run.
- Set reclaim policy intentionally, then test delete and cleanup behavior under churn.
- Prefer resizing over over-allocation, and audit capacity drift regularly.
- Add QoS where multi-tenant load causes tail spikes, especially on shared NVMe/TCP fabrics.
- Test snapshot and clone workflows during busy periods, not only in quiet labs.
Provisioning Models Compared
The table below shows common approaches and what they usually mean for speed, control, and Day-2 work.
| Model | What it optimizes | What to watch | Typical fit |
|---|---|---|---|
| Static PVs (pre-created) | Predictable inventory | Manual work, drift, and slower change control | Legacy processes, small clusters |
| Dynamic provisioning with simple tiers | Fast delivery | Policy gaps if tiers grow uncontrolled | Most Kubernetes Storage platforms |
| Topology-aware provisioning | Correct placement | Label hygiene and scheduling alignment | Multi-zone clusters |
| NVMe/TCP-backed dynamic volumes with QoS | Performance plus isolation | Fabric discipline and SLO tuning | Databases, analytics, shared platforms |
Predictable Kubernetes Storage with Simplyblock™
Simplyblock™ supports Kubernetes-native provisioning through CSI and emphasizes Day-2 workflows like snapshots, clones, expansion, and automated provisioning. That focus reduces manual effort during growth and during platform upgrades.
For performance-driven stacks, simplyblock pairs Kubernetes Storage automation with NVMe/TCP and an efficient user-space approach aligned with SPDK concepts. This design reduces overhead in the I/O path and helps keep performance steady under load.
Teams can use Simplyblock for disaggregated or hyper-converged layouts, which helps keep one operating model while infrastructure changes. Multi-tenancy and QoS controls help isolate workloads, which supports predictable service levels on shared clusters.
What’s Next for On-Demand Volume Automation
Kubernetes continues to tighten the storage contract around safer defaults, clearer placement behavior, and better lifecycle signals. Expect more emphasis on topology alignment, policy-driven tiers, and richer observability around provision, attach, and mount timing.
On the infrastructure side, faster Ethernet and better congestion control reduce the penalty of remote access. DPUs and IPUs can also offload parts of the storage path and free CPU for applications. Even with these shifts, platform teams still win or lose on consistency: StorageClass design, QoS discipline, and clean lifecycle automation.
Related Terms
Teams often review these glossary pages alongside Dynamic Volume Provisioning when they standardize Kubernetes Storage and Software-defined Block Storage.
Questions and Answers
Dynamic provisioning allows Kubernetes to automatically create persistent volumes when a pod requests storage. It eliminates the need for manual volume creation and is crucial for automated infrastructure management in fast-scaling, cloud-native environments.
When a PersistentVolumeClaim (PVC) is created, the CSI driver provisions a new volume based on the StorageClass parameters. This enables on-demand volume creation for workloads like PostgreSQL on Kubernetes, ensuring rapid, consistent resource delivery.
It improves agility by enabling developers to request storage without operator intervention. It also supports cost optimization through thin provisioning, automated sizing, and workload-specific classes—all of which reduce overprovisioning and manual errors.
Yes. CSI drivers like Simplyblock’s support encrypted dynamic volumes, allowing you to meet compliance and security standards automatically. These volumes are provisioned with encryption at rest enabled, without additional configuration.
Absolutely. It’s particularly valuable for stateful workloads in Kubernetes, allowing persistent volumes to be provisioned per pod without delay. Combined with snapshots and replication, it ensures reliability and performance for critical data services.