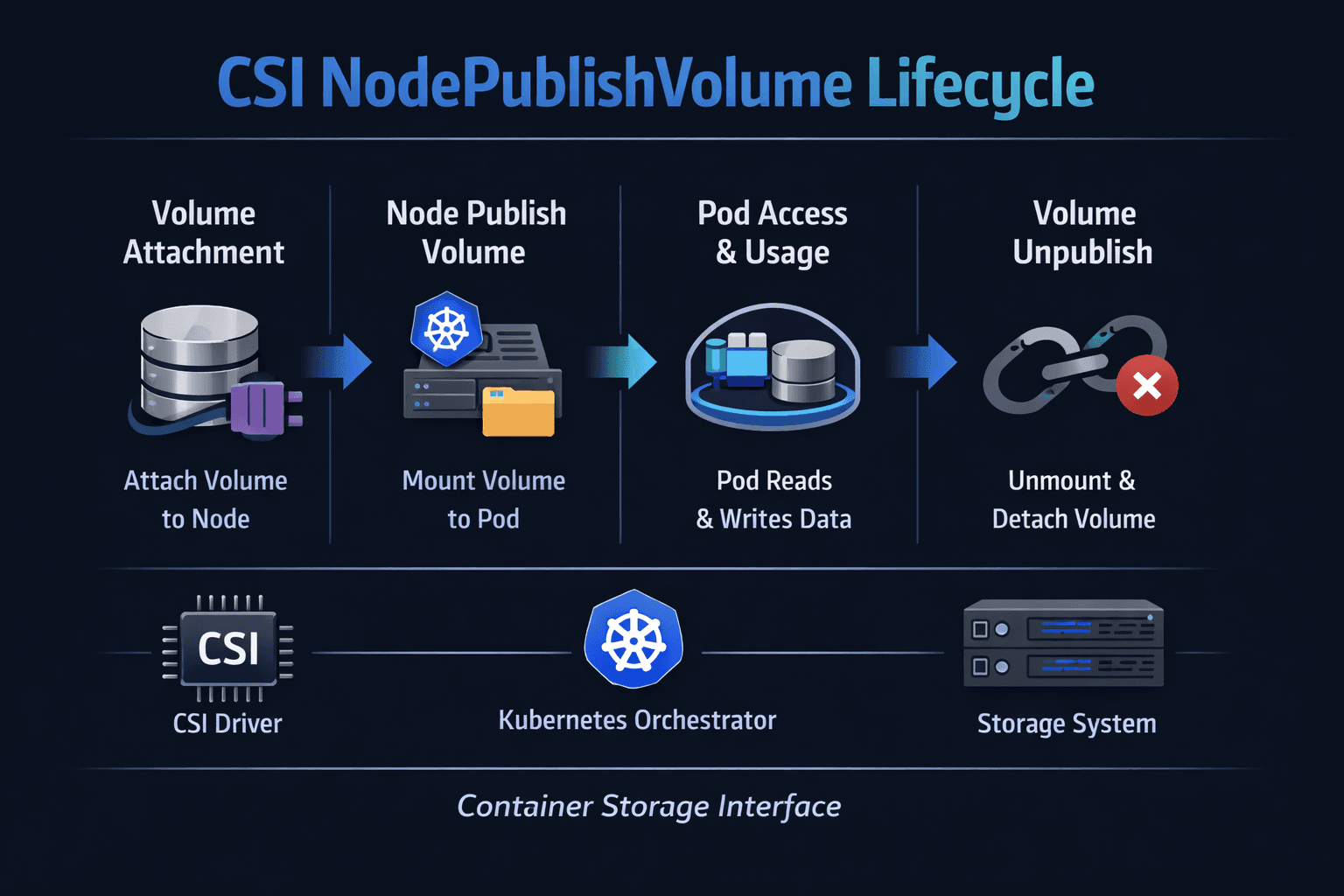
CSI NodePublishVolume Lifecycle
Terms related to simplyblock
CSI NodePublishVolume is the node-side CSI call that turns a provisioned volume into a usable mount (or raw block device) inside a pod. Kubernetes triggers it when the kubelet prepares a pod sandbox and needs the volume ready at the target path on a specific node. In practice, this “publish” step often decides whether a Stateful workload starts in seconds or stalls on storage operations.
What is the lifecycle, in plain terms? The kubelet asks the CSI node plugin to publish a volume, the plugin confirms the device path and mount settings, then it mounts (or bind-mounts) the volume into the pod’s volume directory, and finally, the kubelet can start containers that rely on that path.
What usually breaks? Teams most often hit delays in device discovery, multipath settling, mount option mismatches, node plugin throttling, and networked storage reconnects during node pressure events.
Faster publish operations with newer CSI patterns
Executives care about the lifecycle because it shows up as lost availability and longer recovery time during node rotations, upgrades, and autoscaling events. Platform teams care because NodePublishVolume sits on the critical path for pod scheduling and restart loops.
You get more predictable outcomes when the storage platform provides stable device identities, consistent attach semantics, and clear observability per mount attempt. You also reduce variance when you keep the data path CPU-efficient, because the same nodes that run workloads often run storage clients, cgroups, and kubelet control loops at the same time.
🚀 Standardize NodePublishVolume behavior across clusters with NVMe/TCP-backed volumes
Use simplyblock to keep Kubernetes Storage predictable with Software-defined Block Storage and QoS controls.
👉 Install simplyblock CSI via Helm →
CSI NodePublishVolume Lifecycle in Kubernetes Storage control loops
Within Kubernetes Storage, NodePublishVolume interacts with several moving parts: the scheduler places the pod, the kubelet manages volume setup, and the CSI node plugin performs the publish operation. If your driver uses NodeStageVolume, the system typically stages once per node and then publishes per pod. If your driver skips staging, it may do more work during each publish call.
This matters for scale because Stateful deployments often create many concurrent publish calls during rolling updates. When the node plugin serializes too aggressively, startup latency increases. When it parallelizes without guardrails, it can overload the node with mount and NVMe discovery work.
To keep Kubernetes Storage steady, operators usually align three things: mount concurrency limits, node resource reservations, and consistent StorageClass parameters. Those choices set the floor for predictable behavior across clusters.
CSI NodePublishVolume Lifecycle and NVMe/TCP data paths
NVMe/TCP changes the performance profile of “publish” because the attach and discovery path can complete quickly, but only when the initiator configuration stays consistent across nodes. NVMe/TCP also raises the stakes for correctness: a small mismatch in subsystem discovery, multipath settings, or timeouts can turn a fast path into repeated reconnect loops during node drains.
For Software-defined Block Storage, NVMe/TCP also increases the value of user-space and zero-copy optimizations, because CPU cycles often become the real bottleneck during mass pod restarts. If the node spends less CPU time per I/O and per reconnect, kubelet and the CSI node plugin both stay responsive under pressure.
Measuring publish-time impact without guessing
Most teams measure workload latency and miss the real blocker: time-to-ready volume. A practical benchmark focuses on “pod scheduled → containers running,” and then isolates the storage portion.
Start with these questions because they fit featured snippet-style reporting:
How do you measure NodePublishVolume time? Capture timestamps for kubelet volume setup and correlate them with CSI node plugin logs for the same PVC and pod UID.
What is a good target? Targets vary by environment, but teams often aim for consistent publish times under load rather than chasing a single best-case number.
When you benchmark, keep test conditions stable: same node type, same kernel and initiator settings, and the same number of concurrent pod starts. Then add controlled stress, like rolling a node pool or restarting a StatefulSet replica set, and watch for tail spikes.
Operational fixes that reduce slow mounts and retries
Use one change set at a time so you can attribute results. The following actions tend to deliver the fastest wins in production:
- Set clear limits for the CSI node plugin concurrency so mount storms do not starve kubelet threads.
- Standardize mount options across StorageClasses to avoid per-pod differences that trigger remounts.
- Validate NVMe/TCP initiator settings on every node image, including reconnect timing and multipath behavior.
- Reserve CPU for kubelet and the CSI node plugin to prevent noisy neighbors from delaying publish calls.
- Add per-volume QoS controls so background I/O does not inflate publish-time tail latency for foreground restarts.
Publish behavior compared across common storage approaches
The table below summarizes how publishing behavior changes depending on the storage approach. Use it to set policy: you want the simplest lifecycle that still meets availability and performance goals.
| Approach | Where “publish” work happens | Typical failure mode | Operational visibility | Best fit |
|---|---|---|---|---|
| CSI with NodeStage + NodePublish | Stage once per node, publish per pod | Staging succeeds, publish blocks on mount options | Good, if driver logs per call | Large StatefulSet fleets |
| CSI NodePublish-only (no staging) | Kubelet binds the local path | Mount storms during rolling updates | Good, if the driver logs per call | Smaller clusters, simpler ops |
| hostPath / local mount | Mixed, depends on the driver | Node loss equals data loss | Simple, but limited | Caches, scratch, non-critical |
| In-tree legacy plugins | Kubelet + plugin code path | Harder upgrades, drift in behavior | Declining, varies by plugin | Legacy clusters only |
Simplyblock™ practices for consistent node-side volume publishing
Simplyblock integrates with Kubernetes through its CSI driver and supports installation via Helm, which helps standardize the node plugin footprint across clusters. That standardization matters when you scale Stateful workloads because NodePublishVolume behavior depends on consistent node configuration.
In performance-sensitive environments, simplyblock aligns with NVMe/TCP and Software-defined Block Storage goals by focusing on a CPU-efficient data path and predictable controls. When platform teams apply QoS and multi-tenant guardrails at the storage layer, they reduce the blast radius of noisy workloads that otherwise inflate publish-time tail latency during rollouts.
CSI NodePublishVolume Lifecycle roadmap – what platform teams are pushing next
The broader CSI ecosystem continues to improve node-side behavior through clearer lifecycle separation, better observability hooks, and more consistent semantics across drivers. The CSI spec and Kubernetes CSI documentation provide the baseline expectations for node-side operations and driver responsibilities. Kubernetes itself continues to refine volume handling and mount behavior as part of its core storage model.
For operators, the near-term direction stays practical: fewer “mystery stalls,” tighter log correlation per publish call, and fewer node-level surprises during rolling maintenance.
Related Technologies
Teams often review these glossary pages alongside the CSI NodePublishVolume Lifecycle when they harden Kubernetes Storage and Software-defined Block Storage for rolling maintenance and rapid recovery.
SPDK
Zero-Copy I/O
Kubernetes Block Storage
Storage High Availability
Kubernetes NodeUnpublishVolume
Questions and Answers
The NodePublishVolume lifecycle phase is part of the Kubernetes CSI workflow where a volume is mounted to a specific path on the node. This operation is critical for exposing volumes to pods using Kubernetes CSI drivers that manage volume attachment and publishing.
While NodeStageVolume prepares the volume at a staging path, NodePublishVolume makes the volume accessible to the container runtime. Understanding both is essential for troubleshooting mounting issues in persistent volumes and maintaining the reliability of Kubernetes Stateful workloads.
A failure during this phase means the volume cannot be mounted to the target path, causing pod scheduling to stall. Solutions like Simplyblock improve resilience during the Kubernetes CSI publish lifecycle by ensuring retry logic and clear error propagation.
Yes. Features such as mount options, filesystem types, and read-only flags can be configured during the publish phase. When paired with encryption at rest, this phase ensures secure delivery of storage to specific pods.
Absolutely. Both ephemeral volumes and persistent block devices use the NodePublishVolume call. In environments that rely on block storage replacement, this lifecycle step ensures the final link between the CSI driver and pod-level I/O.