Software-Defined Block Storage
Terms related to simplyblock
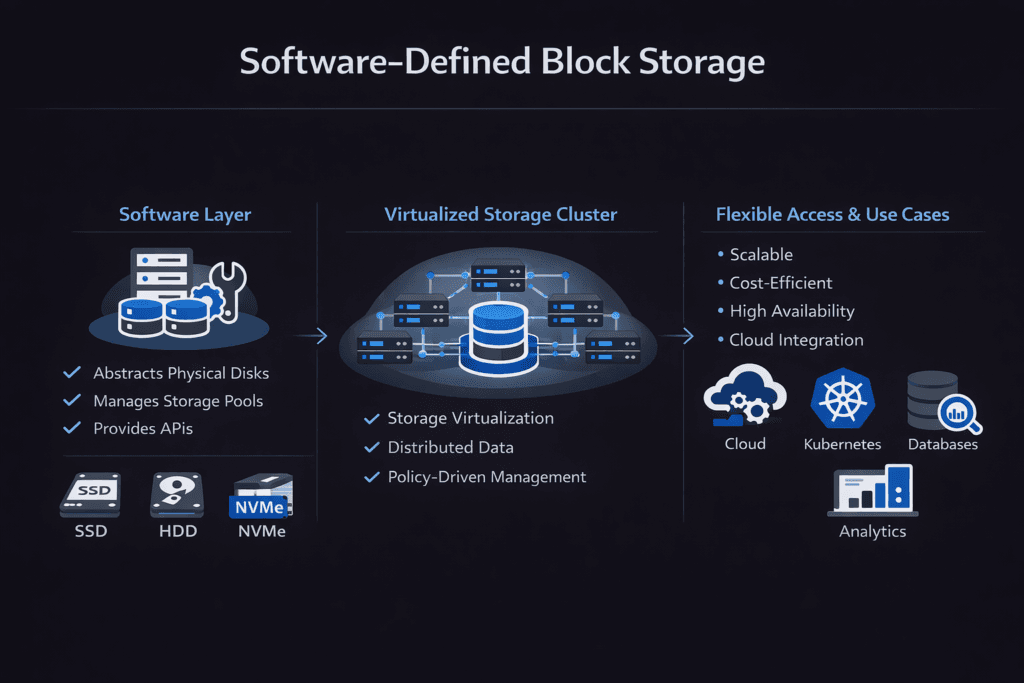
Software-Defined Block Storage is a storage architecture where software delivers block volumes and data services on commodity infrastructure instead of relying on proprietary storage arrays. It abstracts hardware specifics behind a control plane that manages provisioning, placement, resiliency, snapshots, replication, and performance controls. For executives, it reduces vendor lock-in risk and shortens scaling cycles. For platform teams, it brings storage behavior closer to application intent through policies and automation.
This model matters because stateful services rarely break due to average performance. They break due to variance. Predictable latency, steady throughput, and enforceable isolation often decide whether a platform stays stable as tenants, nodes, and workloads grow.
Operating Principles for Modern Software-Defined Storage Platforms
Teams optimize outcomes by designing for repeatable operations and a short, efficient I/O path. A strong architecture limits context switches, reduces kernel crossings, and avoids extra memory copies. These choices improve CPU efficiency and keep behavior steadier at high queue depths, especially on NVMe media.
Day-two operations also drive success. Reliable platforms standardize provisioning, automate rebuild behavior, expose clear telemetry, and apply policy-based controls. When these parts work together, storage becomes easier to run across bare metal, virtualization, and mixed environments.
🚀 Run Software-Defined Block Storage on NVMe/TCP for Kubernetes Storage
Use Simplyblock to standardize multi-tenant volumes, enforce QoS, and cut SAN complexity at scale.
👉 Use Simplyblock for Software-Defined Block Storage →
Software-Defined Block Storage in Kubernetes Storage
Kubernetes Storage benefits from block volumes that follow the same automation model as compute. Software-Defined Block Storage fits well because it can translate a StorageClass request into concrete behaviors like replica policy, failure domain awareness, and performance limits. This mapping helps teams keep consistent outcomes across clusters, regions, and hardware generations.
Architecture decisions still shape performance. Hyper-converged layouts reduce network hops by keeping storage near compute, which can improve latency for stateful services. Disaggregated layouts scale storage and compute independently, which can reduce cost when capacity growth outpaces CPU growth. Hybrid layouts support both patterns in one environment, which helps when a cluster runs databases, analytics, and general services together.
Software-Defined Block Storage and NVMe/TCP
NVMe/TCP carries NVMe semantics over standard TCP/IP networks. This makes it practical for enterprise rollouts because it runs on common Ethernet and fits existing operational tooling. For Kubernetes Storage, NVMe/TCP often becomes a default fabric because it supports broad hardware compatibility and consistent operations across mixed nodes.
NVMe/TCP can raise CPU overhead compared to RDMA-based transports, but disciplined configuration and efficient I/O handling reduce that impact. Many teams standardize on NVMe/TCP for broad deployment while reserving RDMA tiers for strict tail-latency targets. This approach keeps one storage model and avoids fragmented operations.
Measuring and Benchmarking Software-Defined Block Storage Performance
Benchmarking should reflect real workload behavior rather than peak, single-run numbers. A strong test plan defines profiles by block size, read/write ratio, queue depth, and concurrency, then tracks IOPS, throughput, and tail latency over time. Tail latency matters because it drives database timeouts, replication stalls, and user-facing jitter even when averages look fine.
CPU cost per I/O belongs next to every latency chart, especially in Kubernetes. If storage burns too many cycles, platform density drops, and node counts rise. The business impact shows up as higher infrastructure spend and less application headroom.
Approaches for Improving Software-Defined Block Storage Performance
Most performance wins come from cutting variance and enforcing isolation. Use this checklist to guide tuning and validation:
- Keep the data path efficient by avoiding extra copies, minimizing kernel overhead, and using NVMe-friendly queue handling.
- Enforce QoS so noisy neighbors cannot destabilize latency for critical services.
- Match protocol to service level goals by using NVMe/TCP broadly and reserving RDMA tiers for strict p99 targets.
- Validate network consistency, including MTU behavior, buffering, and congestion signals, before changing storage internals.
- Standardize fio profiles and gate changes on p95 and p99 latency, not only average throughput.
Enterprise Block Storage Models Compared
The table below summarizes common approaches to block storage delivery, with emphasis on scalability, control, and predictable outcomes.
| Attribute | Traditional SAN Appliance | Cloud Block (Managed Volumes) | Software-Defined Platform |
|---|---|---|---|
| Scaling model | Scale-up, siloed growth | Provider limits apply | Scale-out across nodes and pools |
| Hardware model | Proprietary, vendor-bound | Provider-managed | Commodity servers and NVMe media |
| Kubernetes fit | Often add-on integration | Works, but cloud-specific | Kubernetes-aligned provisioning model |
| Isolation controls | Array-based policies | Limited knobs | Tenant-aware controls and QoS |
| Protocol path | FC or iSCSI common | Cloud fabric | NVMe/TCP and NVMe-oF variants |
| Cost profile | High CAPEX and support cost | OPEX, can spike at scale | OPEX can spike at scale |
Operational Control and Isolation with simplyblock™
Simplyblock™ targets predictable performance by pairing a distributed control plane with a high-efficiency data path. Its SPDK-based user-space approach reduces kernel overhead and helps keep CPU impact low, which supports steadier latency as concurrency rises. This matters in Kubernetes Storage because scheduling pressure, rebuild work, and multi-tenant traffic often collide.
Deployment flexibility supports real-world constraints. Teams can run hyper-converged for locality, disaggregated for independent scaling, or hybrid layouts for mixed workloads. Multi-tenancy and QoS controls protect critical services from noisy neighbors, while NVMe/TCP provides a practical fabric for broad enterprise adoption. In environments that benefit from offload, designs that align with DPUs or IPUs can reduce host CPU cost and stabilize performance targets.
Roadmap Trends in High-Performance Storage Architectures
Expect tighter determinism and deeper platform integration across the category. Policy-driven placement will align volumes with failure domains and workload classes. Smarter rebuild automation will keep recovery work from disrupting latency targets. Telemetry loops will detect risk earlier and adjust behavior before incidents occur.
The I/O stack direction stays clear. Efficient user-space designs, lower CPU-per-I/O economics, and more offload options will matter as NVMe speeds rise and clusters consolidate more stateful services. Enterprises will favor platforms that keep operations consistent while maintaining performance under change.
Related Terms
Teams often reference these pages with Software-Defined Block Storage.
- Storage Performance Benchmarking
- Storage Offload on DPUs
- Storage Orchestration
- Storage Resource Quotas in Kubernetes
Questions and Answers
Software-defined block storage decouples storage services from hardware, offering flexibility, scalability, and automation. It enables organizations to use commodity servers to provision storage dynamically—ideal for cloud-native stacks, Kubernetes environments, and cost-efficient scaling.
Traditional SANs rely on proprietary hardware and centralized control, while software-defined storage (SDS) uses distributed software to manage volumes across commodity hardware. SDS provides better scalability and automation while reducing vendor lock-in, especially when combined with NVMe over TCP.
Through CSI drivers, SDS platforms like Simplyblock dynamically provision encrypted block volumes within Kubernetes clusters. It supports features like snapshots, replication, and per-volume encryption while delivering NVMe performance to stateful applications such as PostgreSQL and MongoDB.
Yes, modern SDS solutions offer performance and reliability on par with or better than traditional arrays. Features like synchronous replication, instant snapshots, and high IOPS via NVMe make SDS a strong alternative for virtual machines, containers, and bare-metal workloads.
Combining NVMe with software-defined storage dramatically boosts IOPS and reduces latency. When paired with NVMe/TCP, SDS platforms can deliver near-local storage performance over standard Ethernet, ideal for high-throughput or latency-sensitive applications.