Ceph Replacement Architecture
Terms related to simplyblock
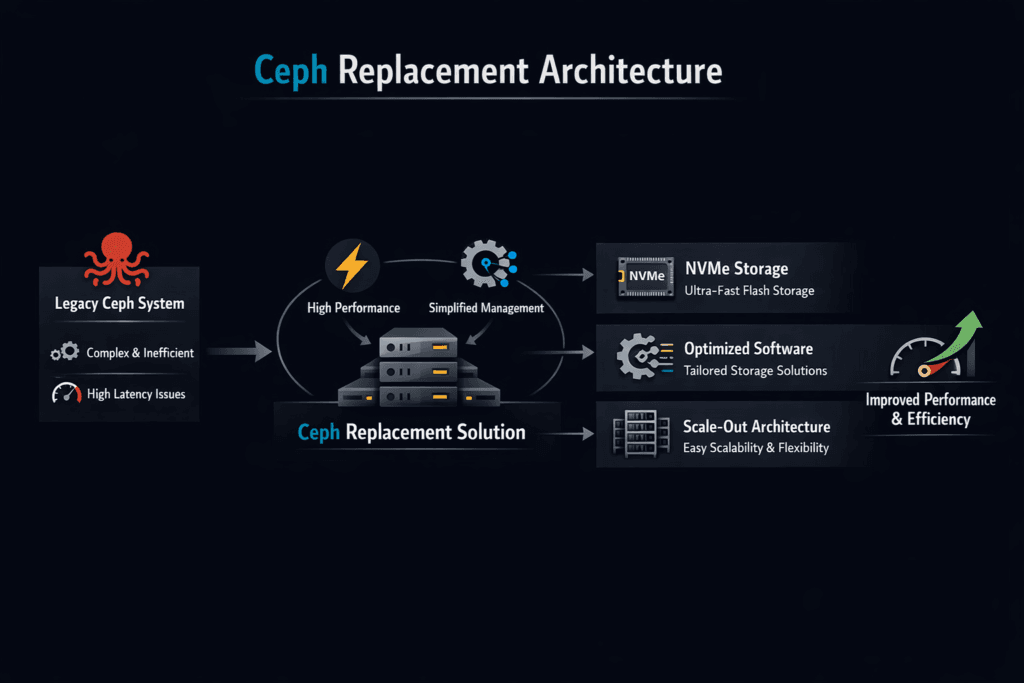
Ceph Replacement Architecture describes the target design you use when you move off Ceph while keeping the same business outcomes: durable storage, elastic scale, and predictable operations. Many Ceph estates hit the same issues over time: uneven tail latency under mixed load, a large ops surface area, and upgrade risk tied to cluster health. A solid replacement plan defines the data path, the control plane, and the day-2 model before any migration starts.
Kubernetes Storage adds more pressure because reschedules, rolling updates, and multi-tenant sharing shift IO patterns every day. A strong design also treats Software-defined Block Storage as a platform service with clear SLOs, not as a shared pool that runs on hope.
What a Practical Replacement Must Deliver
Executives usually want lower risk and lower run costs. Operators want fewer moving parts and simpler upgrades. Workloads want stable p99 latency and fast recovery after node events. A practical design sets these targets up front.
You should scale capacity without forcing a matching compute scale-up. You should keep rebuilding work from crushing production IO. You should isolate tenants so one team cannot distort another team’s latency. NVMe/TCP also needs a clear role in the design because it shapes network load, CPU cost, and performance consistency across clusters.
🚀 Replace Ceph Without Trading Scale for Complexity
Use simplyblock to run NVMe/TCP Software-defined Block Storage with tenant-aware QoS.
👉 Use simplyblock as a Ceph Alternative →
Ceph Replacement Architecture Requirements for Kubernetes Storage
Ceph often enters Kubernetes through an operator layer, and the cluster still inherits Ceph recovery behavior and tuning knobs. That stack can work, but it often pushes platform teams into deep storage ops to keep app teams productive.
A replacement architecture for Kubernetes Storage usually chooses one of three shapes.
Hyper-converged fits teams that want to reuse worker nodes and keep procurement simple. Disaggregated fits teams that want clean fault domains and predictable storage bandwidth. Hybrid fits teams that mix both in one cluster, often by tier. Your topology choice should match your failure model, your budget, and your performance targets.
Ceph Replacement Architecture with NVMe/TCP in the Data Path
Many Ceph clusters rely on TCP/IP networking, but Ceph does not deliver NVMe semantics end-to-end. NVMe/TCP does, and that matters when you want consistent block performance on standard Ethernet.
NVMe/TCP can reduce protocol overhead compared to older storage protocols, and it scales well across common switch fabrics. It also fits Kubernetes Storage because it supports flexible node pools and clear separation between compute and storage tiers. When the data plane runs efficiently, teams can focus on fabric health and workload isolation instead of fighting storage stack overhead.
How to Measure “Better Than Ceph” Without Guesswork
A Ceph replacement needs proof, not opinions. Use workload-shaped tests and track percentile latency. fio can model queue depth, random IO, and mixed read/write ratios, which helps you measure p95 and p99 under real pressure.
Pair IO tests with platform signals so you can explain results to both engineers and finance. Track p99 latency, CPU per IO, rebuild duration, and performance variance during node drains. Measure noisy-neighbor impact by running two tenants at once with different IO patterns. If one tenant can harm another, the platform will not scale as a service.
Steps That Lower Migration Risk
Use a staged move that avoids big cutovers and protects production SLOs. Keep the checklist short so teams actually follow it.
- Inventory which apps need block, which need object, and which can use managed services instead of self-hosted storage.
- Define SLOs for p99 latency, recovery time, and tenant isolation before you select the target platform.
- Stand up the new storage tier in parallel, then migrate one workload class at a time.
- Validate failure drills: node loss, rack loss, and rolling upgrade behavior under load.
- Set per-tenant QoS limits early, then keep them as policy, not as one-off tuning.
- Standardize observability for IO, latency percentiles, and rebuild work across clusters.
Architecture Options Compared – Ceph vs Replacement Designs
The table below compares common Ceph replacement choices by operational load, performance controls, and fit for Kubernetes Storage.
| Option | Primary Strength | Main Tradeoff | Best Fit |
|---|---|---|---|
| Ceph (with an operator layer) | Broad feature scope (block, file, object) | High ops load, deep tuning | Teams with strong storage ops |
| Longhorn | Simple Kubernetes-native install | Performance ceiling for heavy IO | Smaller clusters, lighter IO |
| OpenEBS | Flexible engines and patterns | Variance by engine, tuning needed | Mixed use cases, experimentation |
| Simplyblock Software-defined Block Storage | NVMe/TCP focus, multi-tenancy, and QoS | Block-first scope (vs all interfaces) | Databases, latency targets, shared platforms |
Ceph Replacement Architecture with simplyblock™ for Predictable Operations
Ceph often forces platform teams to become storage specialists. simplyblock™ aims to shrink that ops surface while keeping scale-out behavior, multi-tenancy, and QoS as built-in controls. Multi-tenancy and QoS help cap noisy neighbors and keep latency steady as more teams share the same Kubernetes Storage service.
Simplyblock also aligns the data path with NVMe/TCP and an efficient user-space approach, which helps reduce CPU waste per IO and makes performance scaling easier to budget. That combination fits teams that want strong block storage performance without taking on a large storage ops tax.
Where Ceph Replacements Are Heading Next
Kubernetes platforms keep pushing toward clearer storage health signals, topology-aware placement, and safer rollouts. On the infrastructure side, DPUs and IPUs will take on more networking and storage work, which can reduce host CPU pressure and help stabilize tail latency.
NVMe/TCP adoption will likely continue because it fits standard Ethernet, scales across node pools, and supports disaggregated storage designs without exotic fabrics.
Related Terms
These pages support planning and validation for Ceph Replacement Architecture.
Questions and Answers
Ceph can be complex to operate, resource-intensive, and difficult to scale efficiently in performance-sensitive environments. Replacing it with a software-defined NVMe storage solution like Simplyblock simplifies deployment while improving throughput and latency for Kubernetes or VM workloads.
Simplyblock provides a distributed, scale-out architecture using NVMe over TCP, offering lower latency, better performance, and simpler management than Ceph’s object-based backend. It is ideal for stateful applications requiring predictable performance.
Yes. Simplyblock integrates via CSI, enabling seamless transition of persistent workloads. It supports stateful Kubernetes workloads with features like encryption, replication, and snapshots—offering a drop-in alternative to Ceph’s RBD volumes.
Workloads requiring low-latency block storage—like databases, queues, and analytics engines—often perform better on systems like Simplyblock that use block-native NVMe architectures over traditional Ceph object layers.
Unlike Ceph’s layered and monolithic architecture, Simplyblock provides modular storage services with simplified scaling, monitoring, and maintenance. It enables easier multi-tenant deployments with built-in data services across dynamic environments.