Incremental Backup
Terms related to simplyblock
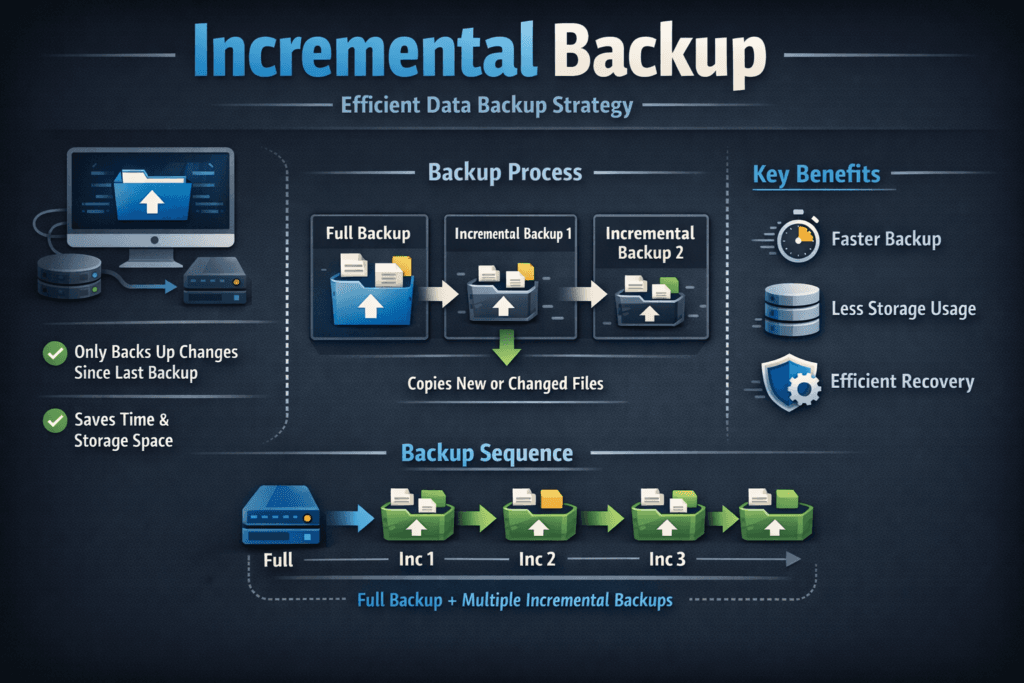
Incremental backup saves only the data changes since the last backup of any type. Differential backup saves all data changes since the last full backup. Over a backup cycle, incremental jobs stay small, while differential jobs grow until the next full backup.
The difference matters most when you plan for two things: the backup window (how fast you can take backups) and the restore chain (how many backup sets you must apply to recover). Incremental backup usually finishes faster and uses less space, but it can slow down restore because you must replay more steps. Differential backup usually restores faster because it needs fewer steps, but it can take longer to run as changes add up.
Optimizing Incremental Backup vs Differential with Modern Solutions
Teams optimize these two backup styles by matching them to workload change rate, retention rules, and recovery targets. A fast-changing database often benefits from frequent incremental backups because they keep backup jobs short and reduce IO spikes. A system with strict restore-time goals often leans toward differential backups because it reduces the number of artifacts needed during recovery.
Modern platforms also reduce the cost of both approaches when they pair backups with snapshots, copy-on-write mechanics, and smart replication. This is where Software-defined Block Storage can help, because it gives operators policy controls for performance, isolation, and data protection across many workloads.
🚀 Keep Kubernetes Backups Fast, Even Under Heavy Write Load
Use Simplyblock to run snapshot-led backups on NVMe/TCP with steady performance and clean restores.
👉 Use Simplyblock for Kubernetes Backup →
Incremental Backup vs Differential in Kubernetes Storage
In Kubernetes Storage, backups interact with volume snapshots, CSI behavior, and scheduling. Many teams use CSI snapshots as consistent points in time, then move snapshot data to object storage for retention. The backup pattern works best when the storage layer keeps snapshot operations fast and predictable, even under load.
Incremental backups map well to Kubernetes because clusters change often, and stateful workloads produce steady write churn. Differential backups can also fit well, especially when teams want simpler restore steps for critical namespaces. Either way, Kubernetes operators should treat backups as part of day-two operations. A backup policy that ignores rollout cadence, node drains, or reschedules often fails when the cluster needs it most.
Incremental Backup vs Differential and NVMe/TCP
Backup work competes with application IO, so the storage data path matters. NVMe/TCP helps by delivering high throughput over standard Ethernet, which supports disaggregated designs without a complex fabric. For backup jobs, NVMe/TCP can shorten backup windows, reduce queue depth pressure, and keep latency steadier when multiple tenants run backups at the same time.
The storage engine design also matters. An SPDK-based, user-space IO path can reduce CPU overhead in the hot path. That CPU headroom helps when backups trigger background work such as snapshot creation, checksum, compression, or replication. It also helps during restore tests, when you want fast reads without starving the application.
Measuring and Benchmarking Backup and Restore Performance
Measure backup performance with metrics that map to business outcomes. Track backup window length, storage space growth, network egress, and the impact on p95 and p99 latency for the application. To restore, track time to the first byte, full restore duration, and the number of steps required to reach the target point in time.
Run tests that reflect real change rates. Use a write workload that matches your database or pipeline, then compare incremental and differential schedules over the same time span. Include at least one failure-style test where you restore into a clean environment, because restore paths often expose hidden bottlenecks.
Approaches for Improving Backup Reliability and Speed
Treat backups as a production workload, not a background task. The following actions usually deliver the biggest gains (this is the only list on this page):
- Set clear RPO and RTO targets per workload tier, then pick incremental or differential schedules that match those targets.
- Keep backup IO isolated with QoS so a large job cannot crush a latency-sensitive database.
- Use snapshots for fast capture, then ship backup data off-cluster for retention.
- Test restores on a schedule, and include full environment recovery for critical services.
- Watch space growth trends because differential backups can grow quickly between full backups.
Operational Trade-Offs – Incremental vs Differential
The table below compares incremental and differential backups across the areas executives and platform teams care about most: backup time, restore time, risk, and operational effort.
| Factor | Incremental backup | Differential backup |
|---|---|---|
| Data captured | Changes since the last backup | Changes since the last full backup |
| Backup job size | Stays small across the cycle | Grows larger until the next full backup |
| Backup window | Usually shortest | Usually increases as the cycle progresses |
| Restore steps | Full backup + all incrementals in order | Full backup + latest differential |
| Restore time | Often slower due to many steps | Often faster due to fewer steps |
| Risk profile | One missing set can break the chain | Fewer sets reduce chain risk |
| Best fit | Tight backup windows, frequent runs | Faster restore needs, simpler recovery |
Keeping backup chains manageable with Simplyblock™
Simplyblock supports consistent backup behavior by keeping IO efficient and controllable under load. The platform’s Software-defined Block Storage foundation helps teams enforce tenant isolation and QoS so large backup jobs do not crowd out production traffic. With NVMe/TCP, simplyblock can also scale throughput for snapshot-heavy schedules and fast restores over standard Ethernet.
For Kubernetes operators, predictable backups depend on more than raw speed. Operators need stable tail latency, fast snapshot actions, and clear policy control across namespaces and teams. Simplyblock focuses on those operational needs so teams can keep backup windows small and restores dependable.
What to expect next in backup strategy
Backup tooling keeps moving toward fewer moving parts and faster recovery. More teams will blend snapshots, log shipping, and automation to reduce manual restore work. In Kubernetes, this trend pushes platforms to make snapshot and restore actions repeatable across clusters and regions.
At the infrastructure layer, DPUs and IPUs will take on more data-path work, including encryption and network handling. Storage stacks that keep CPU overhead low will gain an edge, especially when backups run alongside IO-heavy databases. As the ecosystem matures, teams will demand clear proof through benchmarks, restore drills, and audit-ready reporting.
Related Terms
Teams often review these glossary pages alongside Incremental Backup vs Differential when they set targets for Kubernetes Storage and Software-defined Block Storage.
- Volume Snapshotting
- Write-Ahead Logging (WAL)
- RPO (Recovery Point Objective)
- Asynchronous Storage Replication
- Incremental Backup vs Differential
Questions and Answers
An incremental backup saves only the data that has changed since the last backup, reducing time, storage, and bandwidth usage. It’s a core feature in modern Kubernetes backup strategies, where frequent snapshots are needed without full duplication.
Unlike a full backup, which copies all data, and a differential backup, which copies changes since the last full backup, incremental backups store only the most recent changes. This makes them faster and more storage-efficient—ideal for cloud-native environments.
In Kubernetes, stateful apps require frequent, low-impact backups. Incremental backup enables fast recovery points without disrupting performance. When combined with CSI-integrated storage, it ensures efficient volume management and data protection.
Yes, Simplyblock provides instant snapshots and clones as part of its software-defined storage stack. This allows incremental backups with minimal overhead and fast recovery, even in high-IOPS environments like databases or ML pipelines.
Incremental backups lower RTO and RPO by enabling more frequent backups with less storage usage. Combined with features like encryption at rest and cross-zone replication, they offer scalable, secure, and resilient backup strategies for modern infrastructure.