Object Locking
Terms related to simplyblock
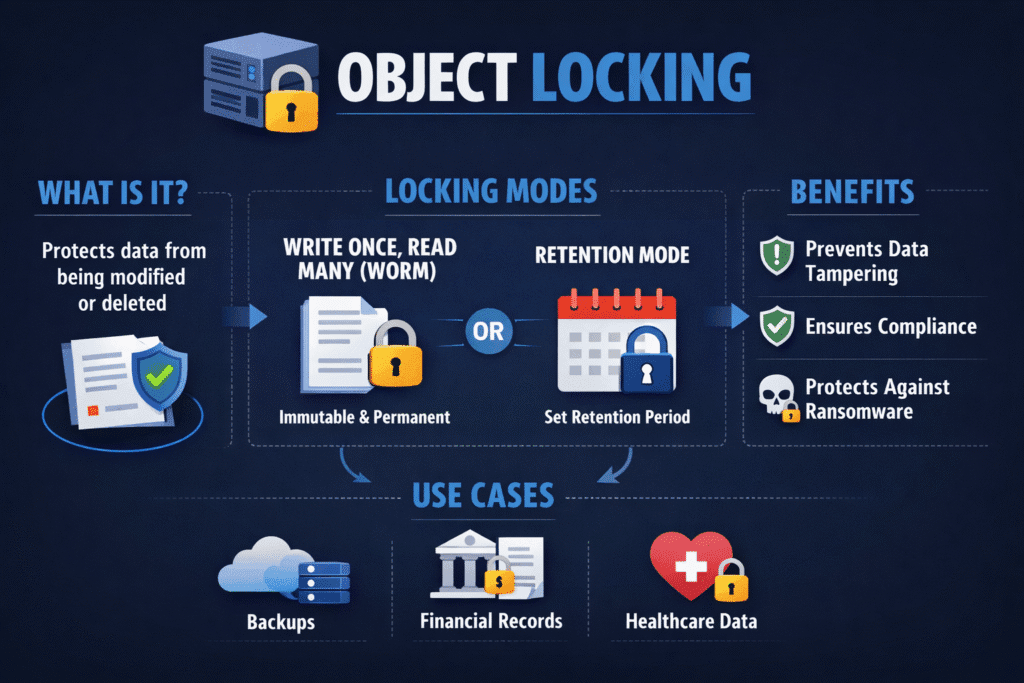
Object Locking keeps an object immutable for a defined time window. It blocks deletes and overwrites until retention expires, so backups and audit data stay intact during mistakes, outages, or ransomware. Most teams implement it in S3-compatible object storage with versioning enabled, so every change creates a new version while the platform protects the retained versions.
Object Locking fits executive risk goals because it adds a hard control that identity policies alone cannot guarantee. Even strong IAM rules can fail during an account takeover. Immutability gives Security and IT Ops a last line of defense when an attacker tries to erase recovery points.
Why Object Locking Matters for Ransomware-Resistant Backups
Ransomware often targets backups first. Attackers delete old restore points, encrypt the current ones, and then demand payment. Object Locking breaks that playbook by forcing a time delay between “malicious delete” and “actual delete.”
Most implementations use two retention modes plus an optional legal hold. Governance mode lets authorized admins bypass retention under strict controls. Compliance mode blocks bypass, even for admins, until the clock runs out. Legal hold ignores the retention date and keeps data protected until someone removes the hold. These options let you match control strength to business risk, audit needs, and regional rules.
🚀 Enforce Immutable Backups Without Slowing Kubernetes Storage
Use simplyblock to keep backup streams fast and predictable on NVMe/TCP with Software-defined Block Storage.
👉 See how simplyblock supports ransomware-resilient backup performance →
Object Locking Patterns for Kubernetes Storage
Kubernetes Storage usually protects live data with Persistent Volumes, then exports backups to an object store. Object Locking works best at the backup layer, not on the primary block device. That split keeps database latency stable while still giving you immutable restore points.
A common pattern looks like this – your backup tool takes a volume snapshot, streams the snapshot data into an object repository, and then applies retention at the object level. When you run multi-tenant clusters, you should also separate repositories by tenant or environment so that a single credential leak cannot affect every backup set.
Software-defined Block Storage strengthens this workflow by keeping snapshot creation fast and predictable. It also helps when different teams share the same platform, because policy controls can limit how much backup I/O any one namespace can push at once.
NVMe/TCP and Shorter Backup Windows
Backup jobs stress the storage path with long reads and sustained writes. NVMe/TCP helps because it supports disaggregated storage over Ethernet while keeping the NVMe command model. That matters when the cluster must move a lot of data quickly, especially during nightly backups or incident response.
For Kubernetes Storage, NVMe/TCP can shorten backup windows by raising available throughput without forcing a legacy SAN design. You can scale bandwidth by adding storage nodes, then keep compute independent. That architecture also reduces “hot node” risk that often appears when backups hammer local disks on a few workers.
Measuring the Real Cost of Immutability
Object Locking changes how long data stays on disk. That sounds obvious, but teams often miss the second-order impact: version growth. Versioning plus retention can multiply stored bytes when workloads write frequent deltas.
Track four numbers to keep this under control: ingest rate, retained days, version count per object key, and restore test frequency. Pair those with p95 and p99 latency on your primary volumes, because backup traffic can create user-visible jitter when the platform lacks isolation.
Ways to Reduce Cost Without Weakening Protection
- Use dataset classes, and set different retention for databases, logs, and long-term archives.
- Rotate object keys by backup job or time window to avoid extreme version fan-out on a single key.
- Limit backup concurrency per tenant, and schedule heavy jobs away from peak transaction hours.
- Validate restores on a cadence, then delete unneeded test copies through approved workflows.
- Enforce QoS on the primary storage layer so backup reads do not starve application reads.
- Keep retention policies simple enough that Ops can explain them during an incident review.
Object Locking Compared to Snapshots and Replication
Each protection control targets a different failure mode. The table below highlights where each one helps and where it falls short, so teams can build a layered plan.
| Control | What it protects | What it does best | Main trade-off |
|---|---|---|---|
| Object Locking | Backup objects | Prevents delete and overwrite for a set period | Higher stored bytes from retained versions |
| Volume snapshots | Primary volumes | Fast rollback and quick local recovery points | Shared failure domains if you store snapshots close to primaries |
| Replication | Data copies across nodes or sites | Availability and DR during outages | Copies bad writes unless you add point-in-time recovery |
| Access controls | APIs and users | Least privilege and audit trails | Compromise can still remove data without immutability |
Simplyblock™ for Predictable Backup Streams
Simplyblock™ focuses on predictable performance for stateful platforms, so backup traffic does not turn into a latency event. With Kubernetes-native integration and policy controls, platform teams can standardize provisioning while keeping noisy backup jobs from overwhelming critical workloads.
NVMe/TCP support helps you build a SAN alternative that scales throughput for snapshot reads and backup exports. Software-defined Block Storage adds the control layer you need for multi-tenant clusters, including isolation and QoS, so foreground traffic stays stable while backups run.
What Platform Teams Should Expect from Object Immutability Controls
Teams increasingly treat immutability as a platform default, not a special feature. Expect tighter ties between retention, audit logs, and automated incident playbooks. You will also see more fine-grained controls around privileged bypass, plus clearer reporting on version growth and retention-driven capacity use.
On the infrastructure side, faster storage paths will keep pushing backup windows down. That shift matters because short windows reduce the time attackers have to interfere, and they also reduce the operational pain of long-running backup jobs in shared Kubernetes environments.
Related Terms
Teams often review these glossary pages alongside Object Locking when they design immutable backup retention and recovery paths.
Questions and Answers
Object locking prevents data from being modified or deleted for a defined retention period. This write-once-read-many (WORM) approach is highly effective against ransomware, as it makes data immutable even if attackers gain access. Paired with features like data-at-rest encryption, it adds a robust layer of defense.
Unlike traditional backups, object locking enforces immutability at the storage level, making it impossible to alter or delete protected data until the lock expires. This ensures recovery points remain untouched, which is crucial for regulatory compliance and rapid disaster recovery, especially in modern Kubernetes environments.
Yes, many cloud-native storage solutions now support object locking for compliance and security. Platforms that integrate with NVMe-over-TCP or offer software-defined storage often include this feature to protect critical data in distributed environments.
Use object locking when you need to ensure data immutability for compliance, legal holds, or to guard against malicious deletion. It is particularly valuable in database backup and archive use cases where data integrity is non-negotiable.
While Kubernetes doesn’t natively support object locking, storage providers like Simplyblock offer secure volume provisioning with immutability features. Through CSI integration, developers can achieve protection similar to object locking on persistent storage.