Operational Overhead of Distributed Storage
Terms related to simplyblock
Operational overhead of distributed storage is the ongoing effort required to keep a scale-out storage cluster reliable, cost-efficient, and predictable as it grows. Teams absorb this overhead through upgrades, incident response, capacity planning, rebalancing, and performance isolation across tenants and workloads.
In Kubernetes Storage, overhead also shows up in CSI lifecycle timing. When PVC provisioning slows down, or attach and mount operations lag during rollouts, the platform team loses release velocity and spends more time triaging storage-related incidents. Kubernetes expects declarative results, so storage operations must stay consistent even when nodes drain, pods reschedule, and background jobs run.
Operational Overhead of Distributed Storage – Modern Optimization
Modern platforms reduce overhead by turning runbooks into policy and automation. Automation matters because it shrinks manual touchpoints during routine events such as scale-out expansion, node replacement, and rebalancing after failures. It also reduces knowledge silos, so storage operations do not depend on a small group of experts.
Architecture drives overhead, too. SPDK-style user-space I/O paths can improve CPU efficiency and reduce kernel overhead that often turns into latency spikes under pressure. When a platform applies this approach to Software-defined Block Storage, teams can standardize operations across baremetal and virtualized nodes without building a custom fast path from scratch.
🚀 Cut Day-2 Storage Ops Load for Kubernetes Databases on NVMe/TCP
Use Simplyblock to reduce noisy-neighbor incidents and keep latency predictable during churn.
👉 Deploy Simplyblock Now →
Operational Overhead of Distributed Storage in Kubernetes Storage
Kubernetes adds operational surface area that can inflate overhead if the storage layer is not Kubernetes-native. StorageClasses, topology constraints, node drains, and CSI upgrades all affect how often operators intervene. A healthy setup keeps volume provisioning and attach behavior predictable during routine churn, not only during steady state.
Many teams lower operational overhead by limiting special cases. They keep a consistent operating model across hyper-converged and disaggregated nodes, and they isolate performance tiers through clear StorageClasses. This approach helps platform teams debug issues faster because fewer variables change at once.
NVMe/TCP and Day-2 Complexity
NVMe/TCP reduces operational friction because it runs over standard Ethernet and aligns with familiar network tools, processes, and team skills. This makes it easier to deploy NVMe-oF without specialized fabrics, which simplifies procurement, troubleshooting, and change control.
TCP uses the host CPU, so implementation quality matters. User-space designs can improve IOPS-per-core and help keep tail latency steadier during rollouts, rebuilds, and bursty workloads. Many teams use NVMe/TCP as the default pool and reserve RDMA for a separate tier only when strict latency goals justify deeper network tuning.
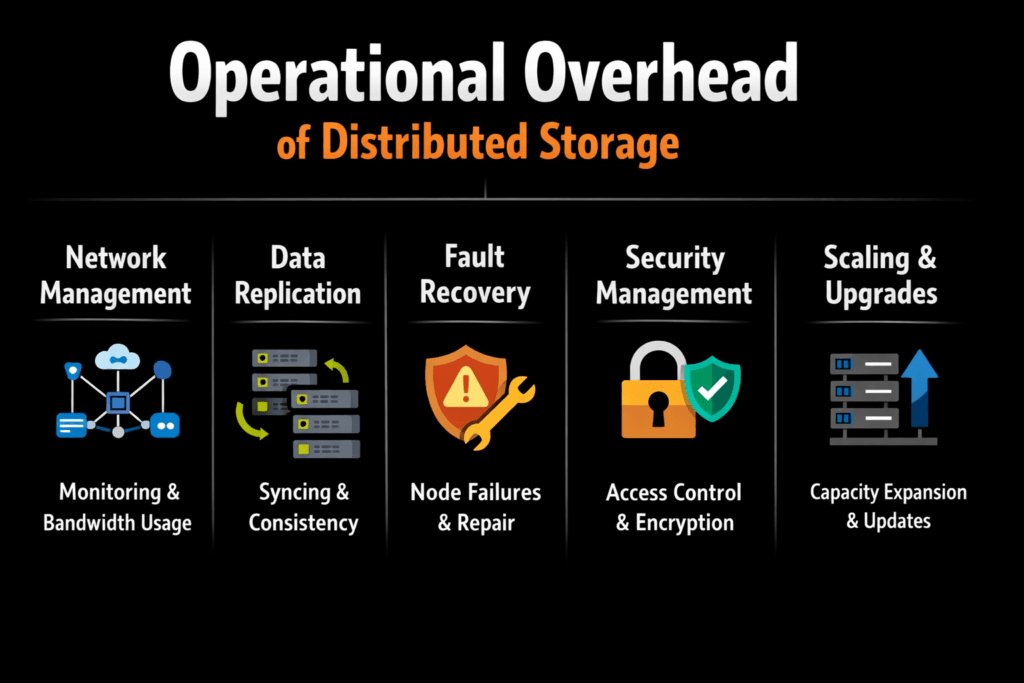
Operational Overhead of Distributed Storage – Measuring and Benchmarking Performance
Benchmarking must reflect operational reality, not just peak throughput. Track p95 and p99 latency, CPU per IOPS, rebuild duration, and the number of operator touchpoints per month, such as manual throttles, emergency rebalances, and noisy-neighbor escalations. Tail metrics matter because slow outliers drive queueing, retries, and user-visible stalls.
In Kubernetes Storage, separate the control plane and data plane measurements. Control-plane signals include PVC-to-ready time, attach and publish time, drain-and-reschedule duration, and snapshot timing. Data-plane signals include latency percentiles, throughput, and IOPS at realistic queue depth. Repeat tests during churn events to capture the behavior that actually drives day-2 load.
Practical Tuning Levers
Reducing operational load usually comes from fewer exceptions and stronger guardrails. Standardize on a small set of pools, enforce storage QoS early, and treat rebuild and rebalance work as governed activity instead of unmanaged background noise. QoS and multi-tenancy prevent one tenant from destabilizing shared performance, which reduces pages and limits reactive tuning.
- Standardize on NVMe/TCP for the default pool, then isolate RDMA to a dedicated tier when strict latency goals justify extra network work.
- Re-run workload tests during drains, upgrades, and rebuild activity, and report percentiles rather than averages.
- Enforce tenant limits with storage QoS so teams stop firefighting noisy neighbors and start meeting SLOs.
- Watch I/O contention signals, then fix placement and throttles before queues explode.
Operational Overhead Comparison Across Architectures
The table below summarizes how operational burden shifts based on architecture choices that leadership teams approve.
| Area | Traditional SAN / Appliance | DIY Open-Source SDS Stack | Simplyblock Software-defined Block Storage |
|---|---|---|---|
| Day-2 operations | Vendor workflows and change windows | Runbook-heavy and tuning debt | Policy-driven ops aligned to Kubernetes Storage |
| Kubernetes integration | Add-ons vary by vendor | Depends on driver maturity | CSI-first model with Kubernetes-native workflows |
| Network transport | Often siloed fabrics | Mixed choices per team | NVMe/TCP baseline with optional tiering |
| Noisy-neighbor control | Limited | Often custom | Multi-tenancy and QoS built in |
| Predictability under churn | Hardware and vendor dependent | Operator dependent | Focus on repeatable lifecycle behavior |
Predictable Day-2 Operations with Simplyblock™
Simplyblock™ targets operational burden by pairing Kubernetes-native workflows with Software-defined Block Storage designed for multi-tenant clusters. It supports NVMe/TCP for broad compatibility, so teams can run disaggregated designs on standard Ethernet while keeping an NVMe-first operational model.
On the operations side, simplyblock reduces friction through CSI-first provisioning, predictable volume lifecycle behavior, and day-2 features that support workload isolation. That mix helps platform teams reduce performance drift during node drains, upgrades, and capacity expansion.
What Changes Next
Operational overhead will keep dropping as platforms automate more lifecycle steps and as efficient user-space paths improve CPU efficiency under load.
Kubernetes will also keep pushing clearer separation between control-plane timing and data-plane throughput, which helps teams debug faster and reduce escalation loops. Topology-aware behavior will matter more as clusters spread across zones and failure domains.
Related Terms
Teams reference these terms to reduce day-2 work and keep distributed storage operations predictable in Kubernetes Storage.
Questions and Answers
Operational overhead often comes from cluster management complexity, node balancing, monitoring, and failure handling. Traditional systems like Ceph require significant tuning and maintenance, which is why many teams explore a simpler Ceph replacement architecture for modern environments.
Distributed storage introduces challenges such as quorum management, replication coordination, and network tuning. Without automation, scaling nodes and maintaining consistency can increase administrative burden, especially in large-scale-out block storage deployments.
Yes. Modern software-defined storage platforms abstract hardware dependencies and automate provisioning, replication, and failover. This reduces manual intervention and simplifies Day 2 operations across Kubernetes and VM environments.
Native CSI integration streamlines provisioning, scaling, and monitoring within Kubernetes. Simplyblock’s CSI-based architecture minimizes operational friction by automating persistent volume lifecycle management.
Simplyblock delivers distributed NVMe-backed storage with built-in automation for scaling, encryption, and replication. Its NVMe over TCP platform reduces infrastructure complexity while maintaining high performance and simplified cluster management.