Write Coalescing
Terms related to simplyblock
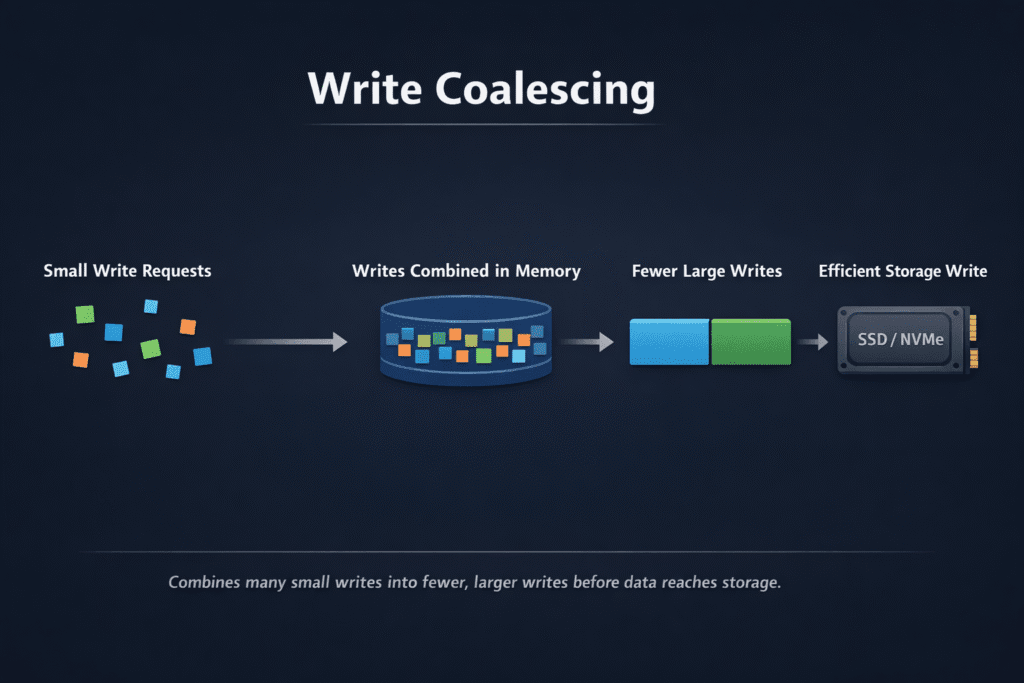
Write coalescing combines many small writes into fewer, larger writes before the storage layer commits data to media. The goal is simple: cut per-I/O overhead, smooth burst traffic, and reduce internal flash work that drives write amplification and SSD wear. SSD controllers often use buffers to gather nearby writes and then program NAND in larger chunks, which improves speed and reduces wear.
You can also see coalescing in the OS block layer. Linux can merge adjacent requests in the queue to form larger operations, which helps efficiency when the workload produces fragmented I/O.
In Kubernetes Storage, coalescing matters most when many pods issue small random writes, such as WAL, compaction, and metadata churn. In Software-defined Block Storage, it becomes a policy and design topic because multi-tenant fairness and tail latency depend on how the system handles bursts, not only peak IOPS.
What Write Coalescing Does in the Storage Stack
Write coalescing works at multiple layers, and each layer has a different “merge unit.” Filesystems may group writes in the page cache, the Linux block layer may merge adjacent requests, and SSD firmware may reorder and consolidate writes in DRAM or SLC cache before it programs TLC or QLC NAND.
Coalescing often improves efficiency because the backend processes fewer operations, which reduces queue pressure, and the SSD spends less time in read-modify-write patterns, which can lower write amplification. It can also keep p95 and p99 latency steadier by reducing micro-bursts of tiny writes that flood queues.
The tradeoff is visibility and control. Coalescing can hide the true application write pattern, and it can shift latency from “many small waits” into “fewer larger waits” if buffer flush timing drifts.
🚀 Smooth Small Writes with Write Coalescing on NVMe/TCP for Kubernetes Storage
Use simplyblock to cut I/O overhead with SPDK acceleration and protect p99 latency under bursty load.
👉 Use simplyblock NVMe/TCP Kubernetes Storage →
Write Coalescing for Kubernetes Storage Under Multi-Tenant Load
Kubernetes Storage amplifies small-write behavior because clusters pack many services onto shared nodes and shared pools. A few pods can create a write storm during restart loops, compaction, or checkpointing, and other workloads feel the impact as tail latency spikes.
Platform teams usually handle this with two controls. First, they set clear tiers and limits through CSI and backend QoS, so one tenant cannot flood the queue. Coalescing helps most when the system keeps flush behavior predictable. Once flush timing turns random, you trade small jitter for big jitter, which hurts databases and queues.
Write Coalescing with NVMe/TCP Paths
NVMe/TCP brings NVMe-oF semantics over standard Ethernet, which makes it practical to scale disaggregated storage without specialized fabrics.
Coalescing pairs well with NVMe/TCP when the data path stays efficient. Kernel copies and interrupt-heavy paths can turn bursts into backlog, and backlog can trigger flush storms and retries. User-space stacks like SPDK reduce overhead and help keep throughput steady during high concurrency, which supports smoother write behavior.
If you benchmark coalescing effects on NVMe/TCP, control OS merge knobs, and measure both throughput and p99 latency. SPDK even notes that disabling merging/coalescing can help when you want precise workload measurements.
How to Measure Coalescing Efficiency and Tail Latency
Start with questions that map to outcomes executives care about. For example, confirm whether you meet latency SLOs during deploys and failure events, whether you protect priority apps from noisy neighbors, and whether SSD endurance burn stays within plan.
Then measure the mechanics. Track tail latency (p95/p99), queue depth, and throttling events, and compare host write rate versus device-level write rate as a practical proxy for write amplification. Also, watch flush frequency and burst size during compaction, backups, and resync windows.
Linux exposes merge behavior through block-layer settings, and it documents request merge concepts and scheduler behavior in official docs.
Practical Tuning Levers That Improve Small-Write Behavior
Use a small set of changes, validate them, and keep the ones that improve both latency and SSD life.
- Set QoS caps per volume or tenant to stop burst writers from starving others, especially in Kubernetes Storage.
- Keep write-heavy logs and compaction traffic on the right tier, and move cold blocks off premium NVMe.
- Align filesystem and application flush settings with the storage tier, so buffers flush in a steady pattern.
- Benchmark with merges on and off to see whether coalescing helps your real workload or just boosts synthetic scores.
Comparing Coalescing Approaches Across Storage Architectures
The table below compares how common designs handle small writes, burst control, and operational effort in shared platforms.
| Approach | Where coalescing happens | Tail-latency risk | Ops effort | Notes |
|---|---|---|---|---|
| Host-only merges (OS + filesystem) | Node block layer | Medium | Low | Works well until multi-tenant bursts collide |
| SSD-only buffering (controller DRAM/SLC) | Drive firmware | Medium | Low | Helps wear and speed, but flush timing can surprise apps |
| Cache layer (write-back cache / log device) | Cache software | Medium to high | Medium | Can smooth writes, but adds policy and failure modes |
| Policy-driven Software-defined Block Storage | Cluster data path + QoS | Low to medium | Low to medium | Stronger isolation and steadier behavior under contention |
How Simplyblock™ Keeps Small-Write Performance Steady
Simplyblock™ targets stable performance under mixed small-write load by combining NVMe/TCP support with an SPDK-accelerated, user-space data path.
In practice, simplyblock focuses on two outcomes that decide whether coalescing helps or hurts: it keeps the I/O path efficient so bursts do not turn into backlog, and it enforces QoS and multi-tenancy so one writer cannot force unstable flush patterns on everyone else.
That combination supports Kubernetes Storage teams that want a SAN alternative built on NVMe-oF behavior, without inheriting classic array limits.
Where Coalescing Techniques Are Moving
Storage stacks keep moving toward tighter control of burst traffic and lower CPU cost per I/O. DPUs and IPUs push more work into the data plane, and that can reduce jitter during high concurrency.
At the same time, platforms add better policy hooks for per-tenant limits, which makes coalescing more predictable in shared environments.
Related Terms
Teams often review these glossary pages alongside Write Coalescing when they tune Kubernetes Storage and Software-defined Block Storage for steady latency and predictable SSD wear.
Write Amplification
Read Amplification
NVMe Multipathing
I/O Path Optimization
Questions and Answers
Write coalescing reduces the number of write operations by combining small, sequential writes into fewer large ones. This minimizes write amplification on SSDs, prolonging endurance—especially in NVMe-powered infrastructures handling high-frequency or streaming data.
In software-defined storage environments, write coalescing helps reduce latency and IO overhead by optimizing how data is flushed to disk. It ensures performance stability across mixed workloads by smoothing out write patterns and reducing backend pressure.
Yes. By minimizing redundant or fragmented writes, write coalescing lowers total write volume—extending SSD lifespan and reducing the frequency of upgrades. When paired with cloud cost optimization strategies, it contributes to both performance and cost savings.
Absolutely. Stateful apps like logs, metrics, or databases in Kubernetes benefit from write coalescing, as it reduces disk wear and IO load. Combined with Simplyblock’s Kubernetes-native storage, it enhances resilience and long-term performance.
Write caching temporarily holds data before writing, while write coalescing intelligently merges multiple write requests. Both reduce IO overhead, but coalescing specifically targets sequential write efficiency—especially beneficial in high-throughput, data-intensive environments.